k3s笔记-04-在边缘部署集群
文章目录
1. 前言
我最初的想法是写一篇关于k3s的高可用实践,但在边缘机房部署集群过程中,发现只依赖k3s并不能完全解决我们的问题,于是在部署过程中做一些基础组件的改造,这里稍作记录,供后续开发时参考。
2. 项目背景
我们的主要业务是在边缘机房搭建边缘云,为用户提供虚拟机、容器服务,典型业务是音视频加速、RTC即时通讯、云游戏等等。
与中心机房(即常见的公有云数据中心)相比,通常边缘机房提供单线和多线带宽资源、支持月95峰值带宽后付费,而中心机房主要提供BGP带宽资源,因此在价格上具有比较大的优势,其次边缘机房的数量多、分布广,能通过同省同区域同运营商覆盖,实现就近访问、降低延迟,以云游戏为例,网络延迟可以控制到10ms以下。
但是边缘机房也存在一些客观的限制条件,例如:
- 资源受限:单机房宿主机数量最低只有两台,最多也不过四十台
- 不定期割接:运营商线路调整、硬件调整、异常事故等相比中心云更频繁,割接期间宿主机可能出现断网、断电重启
- 定期的机房裁撤与上线:运营过程中,为了控制成本和提升毛利率,每月需要对机房进行扩缩容、裁撤、搬迁
- 网络波动:网络设备故障、运营商网络故障、机房带宽跑满等等许多因素,都会导致丢包,因此需要在同线路进行网络质量监控
- 机房运维人员素质参差不齐:边缘机房以托管为主,较少有自建机房,不同地区的机房运维人员素质相差巨大,从误操作导致的故障频率就可以看出
我在加入团队时,现有的服务架构、故障处理流程已经针对边缘环境做了一些解决方案,但是还存在一些问题,主要集中在应用管理与服务发现:
- 应用管理:宿主机装机时会安装一个初始版本程序,后续应用变更时通过pssh批量操作,由于边缘机房宿主机的设备变动频繁(上下线、宕机、临时维修...),导致一些机器可能错过应用更新和系统环境变更
- 服务发现:每个边缘机房都指定了一台宿主机作为入口,中心云调用边缘服务时通过该机器公网IP访问sevrer服务,server服务再根据请求通过内网IP转发到对应的agent模块,另外agent模块也需要通过server转发来访问中心云,该宿主机宕机时,需要及时恢复server服务,否则机房内的服务无法正常使用,通常是一边联系机房人员恢复机器,一边进行server服务的迁移并修改所有机器上的server服务调用IP
与其重新开发一套系统,不如使用k8s,边缘服务容器化很早就被我们leader列入计划中,期望是利用容器化来消除不同宿主机的环境差异,利用service提供服务发现,利用k8s的调度能力实现宕机时的服务漂移。
在开发完一些k8s相关的产品后,我们对集群的运行机制和运维有了一定了解,于是去年年底开始了边缘组件容器化的项目。
3. 为什么选择k3s
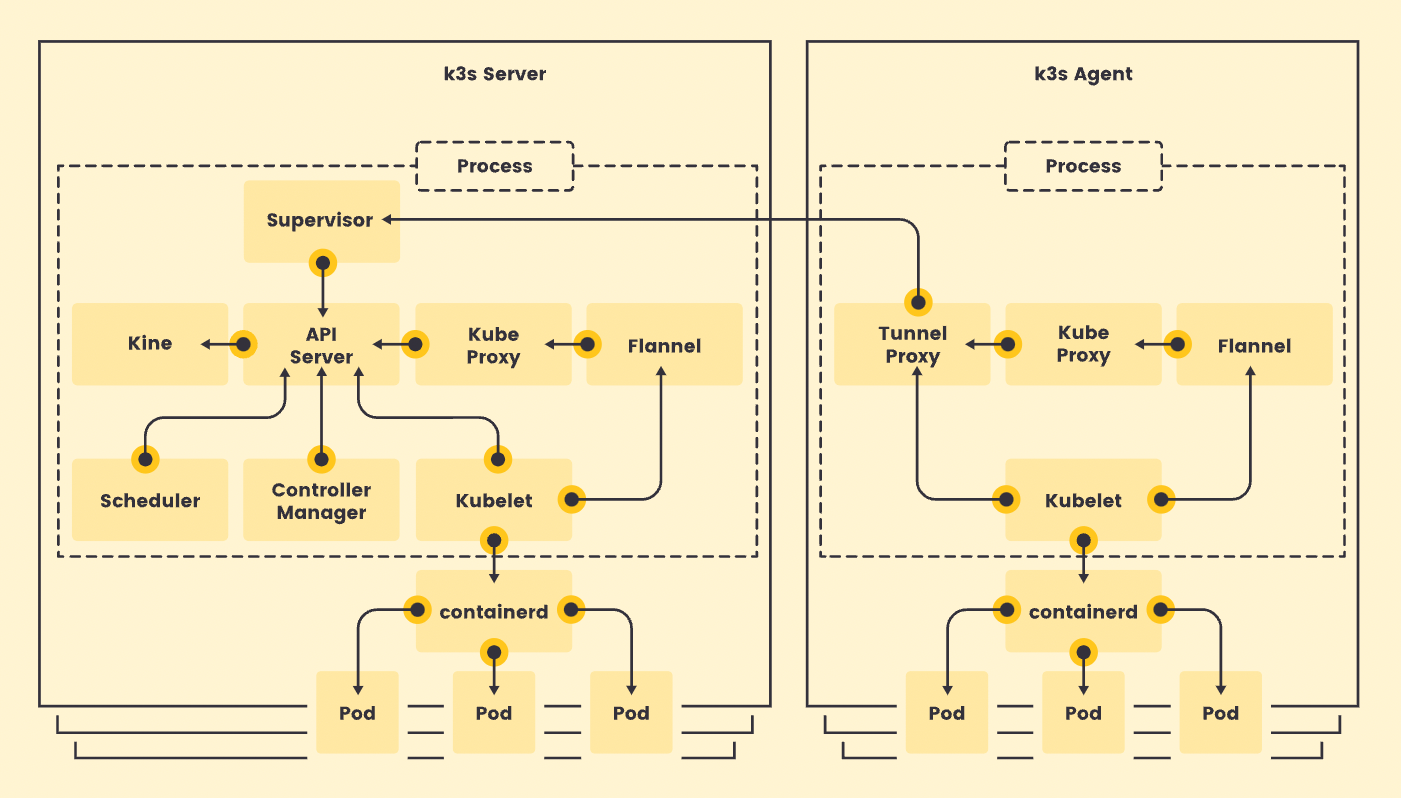
3.1 部署简单
云主机的环境下利用kubeadm部署集群时,默认使用静态Pod在集群中部署核心组件,如kube-apiserver、kube-scheduler、kube-controller-manager、cloud-controller-manager,以及存储集群数据的etcd,如果运行核心组件的Pod异常时,会影响集群运行,为了消除这种耦合,通常会将这些组件剥离出集群来单独维护。
以UCloud的UK8S为例:
- 专有版本: 使用3台master节点创建高可用集群,用户自行选择master节点配置,支撑集群运行的核心组件通过systemd管理,直接跑在master上,master节点对用户可见,而核心组件对用户不可见
- 托管版本: 创建集群后得到的是master节点托管的生产高可用集群,用户无需对master进行运维管理,master节点与核心组件对用户都不可见
其他的厂家产品也大同小异,这里就不详细展开了,基本都是屏蔽部署细节,提供一个开箱可用的集群,而这一点恰好是k3s的优势,可以参考我在去年的博客:k3s笔记-01-部署。
k3s通过定制化配置来简化集群部署,核心组件内嵌在k3s中,只需要单个二进制文件就可以创建集群,维护好k3s服务即可保证集群正常运行,并且从v1.19.5版本开始,k3s内嵌etcd3,进一步简化了高可用集群的部署和维护。
3.2 更适应边缘环境
公有云集群通常都运行在虚拟机中,虚拟机的可用性决定了集群的可用性,以阿里云为例,单ECS实例服务可用性承诺大于等于99.975%,单地域多可用区部署的ECS服务可用性承诺大于等于99.995%,我们可以认为多台ECS组成的master节点几乎不会因为底层介质的原因轻易发生宕机。
私有云集群则通常运行在物理机上,以我们公司内部集群为例,有专门的团队负责运维各地集群供开发人员使用,每个地区的集群都有足够的冗余资源来应对故障,检测到宿主机异常时会提前通知,并安排时间进行Pod漂移和机器下线。
边缘环境的集群同时面临服务可用性低、冗余资源不足的问题,且需要规避宕机引起的集群崩溃,假设节点会随机发生宕机:
- agent节点宕机:集群正常运行,宕机节点上的服务需要迁移至其他节点
- 一半以下的master节点宕机:集群正常运行,除迁移宕机节点上的服务外,需要恢复master节点数量到正常状态
- 一半以上的master节点宕机:集群异常,需要先恢复master节点数量到正常状态,极端情况下需要重新部署集群
我们需要快速恢复或者新建一个master节点的能力,使用k8s时需要重新部署相关的二进制文件或者拉取镜像,而k3s只需要一个二进制文件,配置集群参数后启动k3s服务即可。
3.3 内嵌apiserver-lb
我们的边缘宿主机使用iptables来实现防火墙,子机的防火墙规则是写在宿主机上的,为了避免kube-proxy的iptables规则干扰现有业务,需禁用相关组件,包括:kube-proxy、coredns、flannel等,凡是涉及到访问集群IP的功能都无法使用,所有容器默认使用宿主机网络通信。
k3s在agent模块中提供apiserver的load-balancer,默认监听127.0.0.1:6444,该模块会自动同步所有apiserver的内网地址,访本地地址即可调用apiserver的接口,这使k3s不需要依赖外部VIP就可以实现HA,且k3s中的应用可以绕过service访问apiserver,后面自行实现服务发现时也用到了这个功能。
4. 边缘组件容器化过程
项目主要分成两个部分:
- 服务的容器化改造:包括代码修改、代码编译和镜像打包
- k3s的部署与运维:输出集群部署工具、管理工具和应用部署方案
我主要负责第二项工作,并支持同事完成服务的容器化改造。
4.1 服务容器化
现有服务的调用流程如下:
- 中心服务与边缘Server之间通过 防火墙规则 限制请求来源
- 中心服务需要调用边缘Agent服务时,将携带边缘Agent服务 内网IP 的请求通过 公网 发送给边缘Server,边缘Server接收请求后根据目标内网IP转发
- 边缘Agent需要访问中心服务时,例如上报虚拟机/容器状态,也需要通过边缘Server转发
除此之外,许多Agent服务还存在操作宿主机设备、宿主机网络、挂载磁盘等无法在容器内直接完成的操作。
为了保持现有架构,减少修改,主要做了以下调整:
- 共享除mount以外的所有NS,例如使用宿主机网络、宿主机PID、宿主机信号量等,开启privilege权限,让现有Agent服务能操作所有宿主机资源
- 针对mount命名空间无法共享的问题进行代码适配,除一些默认位置例如tmp、proc等无法直接映射到容器内相同位置的路径,其余自定义路径都挂载到容器内相同位置
- Agent模块使用DeamonSet部署,Server模块使用Deployment部署
- Server访问Agent时使用内网IP,Agent访问Server时使用内部域名,内部域名通过本地DNS服务实现
- 统一基础镜像,基础镜像尽量包含所有服务需要的环境,将不同容器的镜像差异减少到最上层的可执行文件变更,降低服务漂移时拉取镜像的时长
- 统一构建脚本,例如执行make生成二进制文件,make image生成镜像,make image-push推送镜像,并在推送镜像前检查是否存在相同tag的镜像,避免覆盖线上镜像
4.2 集群部署优化
k3s没有提供类似kubeadm的工具,而是使用shell脚本来完成环境检测和参数配置,在需要大规模部署集群时,这种方式略显简陋。
为了进一步简化部署,我修改了安装脚本,并开发了几个辅助模块来管理集群,如下:
安装脚本修改
- 禁用addon组件,包括:coredns,servicelb,traefik,local-storage,metrics-server,这些组件会使用集群网络,无法正常运行
- 禁用集群网络组件,包括:kube-proxy、network-policy、flannel等,使用loopback作为默认CNI插件,在创建Pod时指定使用宿主机网络
- 设置固定的cluster-cidr与serivice-cidr,避免和机房网络冲突
- 使用外部CRI:外部CRI会在启动时监测宿主环境,按需使用overlay或devmapper,且能避免内嵌的containerd在卸载k3s时删除本地镜像缓存
- 删除k3s或k3s-agent服务时,避免删除k3s二进制文件导致需要重新下载
- 按需设置node-name与node-ip,避免宿主机hostname冲突导致异常
- 设置s3相关参数,定时备份etcd
附加模块
- k3s-apiserver:提供api供k3sadm和k3sctl使用
- k3sadm:集群部署工具,支持:
- 初始化部署k3s所需的环境
- 初始化server
- 添加server节点
- 添加agent节点
- 卸载server或agent
- 创建默认ns、secret、clusterrolebinding、serviceaccount等
- 部署附加组件,包括镜像加速、本地DNS、日志采集、集群监控等
- 部署默认版本的边缘服务
- k3sctl:集群管理工具,支持批量部署应用,单个工具可以管理所有集群
4.3 镜像缓存与加速
在完成Dockerfile的优化后,对于单台机器,已经可以利用本地缓存加速下载,但如果服务跨机器漂移时,新宿主机本地可能缺少缓存,因此还需要部署一个机房维度的镜像缓存,这里在前一篇博客已经记录:k3s笔记-03-镜像缓存。
这里使用registry程序来提供集群镜像缓存,该服务可部署在集群中,使用域名访问,服务不可用时containerd会直接从目标仓库直接拉取镜像。
4.4 服务发现
由于移除了访问service的组件,无法通过集群IP访问集群DNS,这里使用本地DNS的方式重新实现了服务发现:
- 所有容器使用宿主机网络
- 每台宿主机上部署了local-dns组件,监听本地127.0.0.1:53,接管所有DNS请求
- local-dns访问127.0.0.1:6444,使用k8s接口watch带有 uec.io/service 标签的Pod,缓存域名与Pod宿主机IP映射关系到本地
- uec后缀的域名视为内部域名,使用本地缓存,其他域名转发到114.114.114.114进行查询
本地域名服务
DNS查询流程
访问内部服务
使用域名访问内部服务的完整流程如下,由于go语言不缓存DNS查询记录,每次请求都会执行DNS查询,再访问目标IP
server组件漂移流程
假设test-server开始部署在master上,接着执行了程序升级,漂移到agent-01上,则访问服务的表现如下:
- master上的test-server容器组开始删除:test-server.uec的DNS记录保持172.16.36.1不变,访问test-server的请求失败
- master上的test-server容器组删除成功,agent-01上开始拉取镜像、启动test-server容器组:test-server.uec的DNS记录保持172.16.36.1不变,访问test-server的请求失败
- agent-01上的test-server启动成功,转为Ready状态:test-server.uec的DNS记录变更为172.16.36.2,访问test-server的请求成功
4.5 监控
因为已经存在一套宿主机监控系统,这里的监控只针对集群和应用开发。
采集程序部署在集群中,利用controller-runtime的选举功能部署多副本,通过k8s的接口采集以下资源上报服务端:
- node:上报节点状态、节点角色
- deployment:上报状态、镜像版本
- daemonset:上报状态、镜像版本
- pod:上报所属工作负载、容器组IP、镜像版本
服务端使用普罗米修斯存,利用自定义规则触发异常推送,将节点或边缘服务的异常通过邮件、短信等推送到值班人员。
5. 最后
在开发过程中,最初由我手动部署集群,由于我们宿主机环境的差异,还遭遇过一次崩溃事件:宿主机重启后hostname发生变化,导致几台master集群无法正常工作,几番折腾也无法修复,最后通过重新部署解决,每台宿主机的hostname也修改为机房内部唯一虚IP,避免重启问题。
经历过几次割接和重启的考验后,运行效果也符合期望,在完善集群部署工具和应用部署工具后,就交付给负责运维的同事部署了,下一阶段是中心云的开发工作,需要完成一个管理边缘集群的内部服务。
无论是k8s还是k3s,我都认为他们只适合私有云或内部服务,不可直接对外提供给用户,如果需要魔改来适配特定环境,k3s是一个更简单的方案。