轻小说文库阅读器–wenku8Reader
原本这个应用叫wenku8Reader,但是后来wenku8的应用出来了,觉得实在不想写了,就搁浅了。后来正好赶上软件工程课设和腾讯面试,就拿它来做个例子,三次面试都讲这个东西,感觉也是斯巴达了,而且跟面试官讲完回来就讲软件工程的中期答辩,结果没准备好,碰了一鼻子灰。
这里放上它的GitHub地址:FinalReader
PS: FinalReader即将更新......这次终于有了一位能做服务器端的小伙伴!!!鼓掌!!!啪滋!啪滋!啪滋!啪滋!快给我数据吧,小伙伴!!~~~2015.10.14
当初重拾的时候,做了很多修改,砍掉了在线书架,写了个单例来替代有点庞大的CoreData管理数据,还有就是把TabBar去掉了,然后就是现在这个样子,有些功能该砍的时候,还是得砍,毕竟建立在十分脆弱的数据源的基础上,想实现复杂的操作也是很苦难。由于在wordpress下调整图片大小会造成模糊,就原尺寸放上了~

然后接下里是阅读器和文库首页,以及对应文库的“更多”和搜索

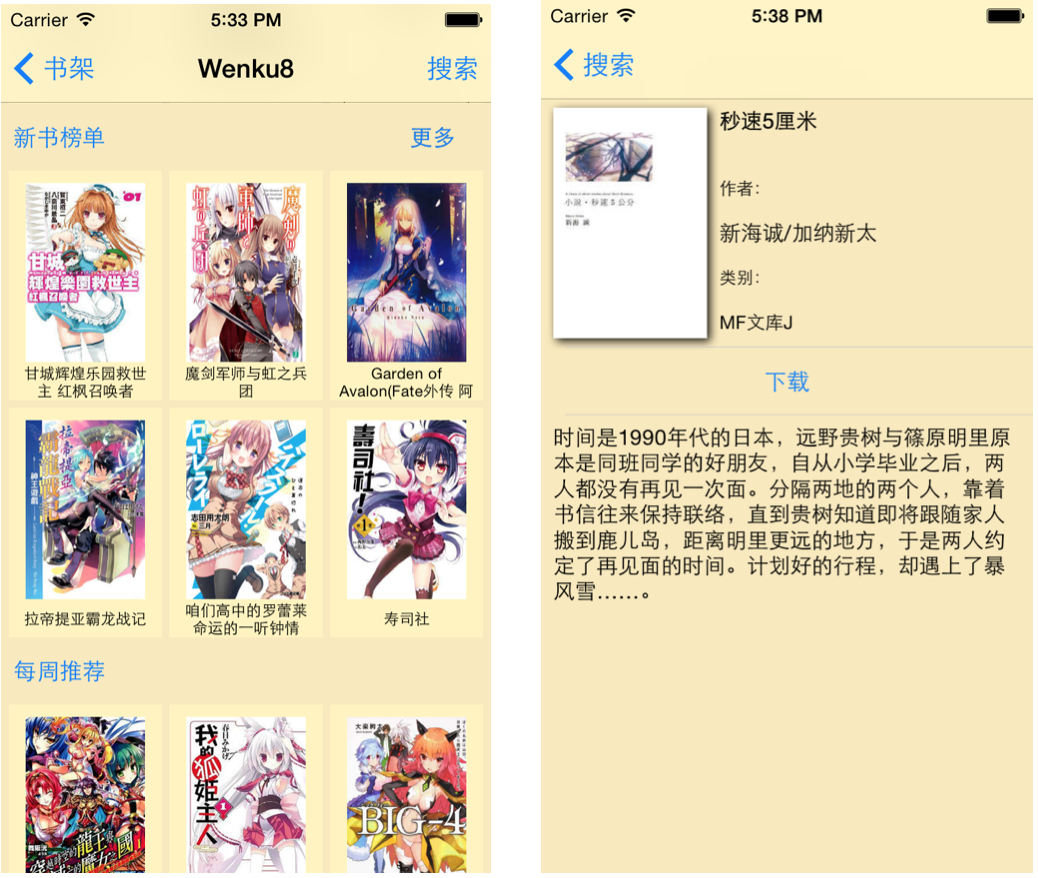
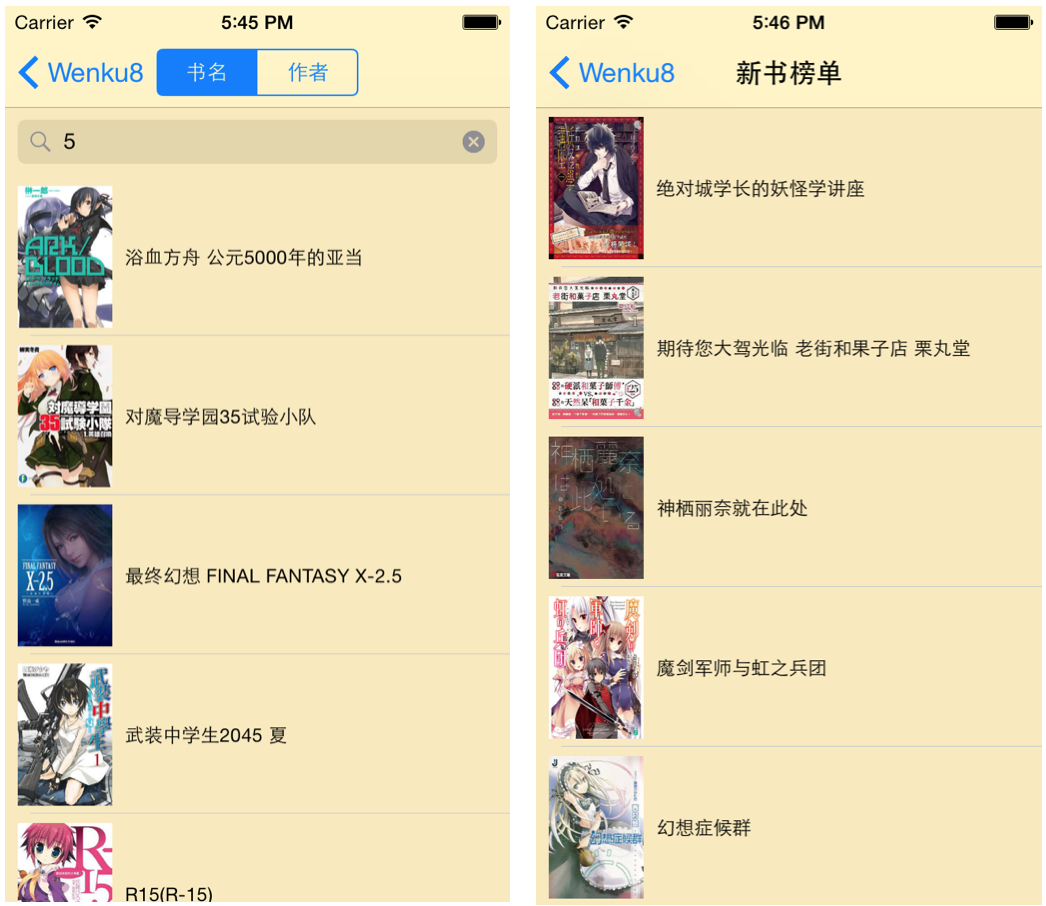
当然,这一切都仅限于4寸的屏幕,还需要iOS8.0以上,不过我想大部分人都会是8.1.2或者8.3的系统吧。
现在开始发表总结感言。
接下来大概是不会更新了,如果有的话,也会是在阅读器的部分(这句话咱都重复多少遍了,但这双手就是停不下来啊),目前阅读器的效率十分令人满意,测试过字体调整,即便不保存结果,也能以小于一duang的速度完成分页并找到当前页面在新分页结果中的位置,前提是一卷的大小,如果是全本的大小,也需要让菊花图徘徊一点时间,这时先做好分卷然后预分页再多线程分页就好,但目前不熟悉正则表达式,暂且搁置。
这个应用还是个人爱好,从最初到现在,都是想写一写来练一练。一开始想做新浪微博客户端,后来被车倒了,选了看上去比较简单的wenku8来自己解析,结果也很凶残,特别是要自己手动来解析每个页面,然后一个一个标签找内容,而第一个版本中还有在线书架的功能,它对应wenku8书架,正好有我想要的更新提醒,只是做起来有点别扭,每次都要先解析,post,再解析,再删除单元格,延迟大,不稳定,假如有api接口,应该一个post然后等确认就够了,果然还是想要自己控制数据啊,但不想再手动解析了,还是开始学习写爬虫或者再做个微博客户端,数据源是最大的痛啊。
尽管如此,我还是学到很多,比如那几篇语言错乱的TextKit学习日记,现在是时候回过头来看看写的东西了。