读书笔记-Docker容器与容器云(第2版)-02
文章目录
3.Docker核心原理
3.1内核知识
namespace实现资源隔离,cgroups实现资源限制,写时复制(copy-on-write)实现高效文件操作。
3.1.1 资源隔离
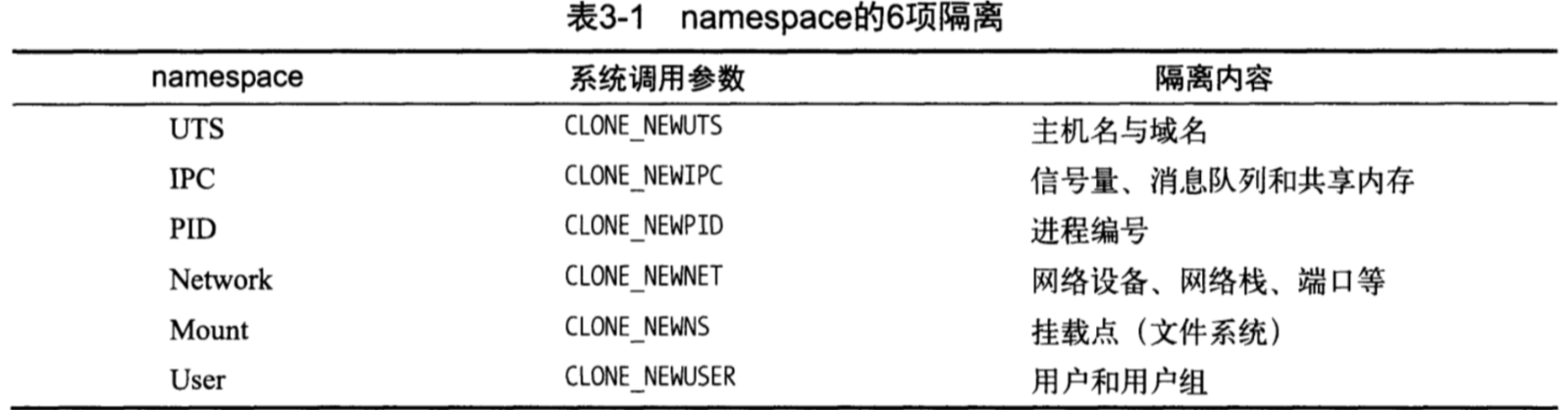
3.1.2 cgroups资源限制
可以简单地将cgroups理解为一个钩子,当申请的资源满足限制条件时就会触发,当然,官方有更详细的定义:
cgroups是Linux内核提供的一种机制,这种机制可以根据需求把一系列系统任务及其子任务整合(或分隔)到按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架。
cgroups的作用:
- 资源限制
- 优先级分配
- 资源统计
- 任务控制
cgoups术语表:
- task(任务):系统的一个进程或线程
- cgroup(控制组):资源控制以此为单位实现,表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统
- subsystem(子系统):资源调度控制器
- hierarchy(层级):由一系列cgroup以一个树状结构排列而成,每个层级通过绑定对应的子系统进行资源控制
组织结构与基本规则:
(1) 同一个层级可以附加一个或多个子系统
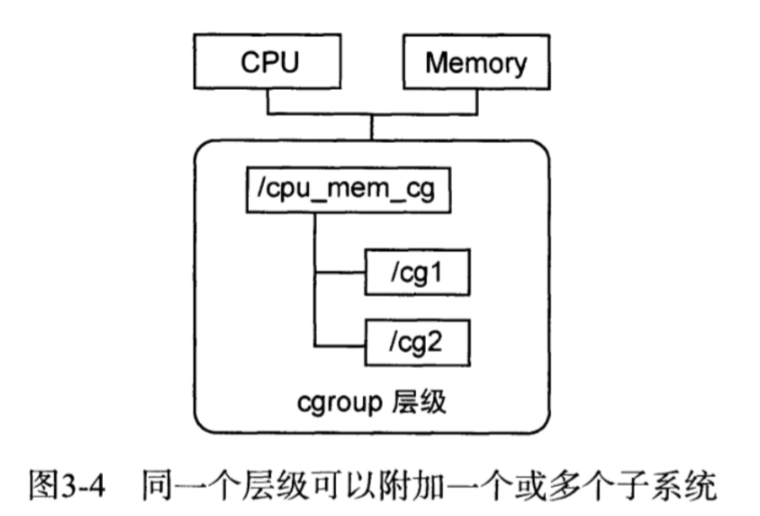
(2) 一个子系统可以附加到多个层级
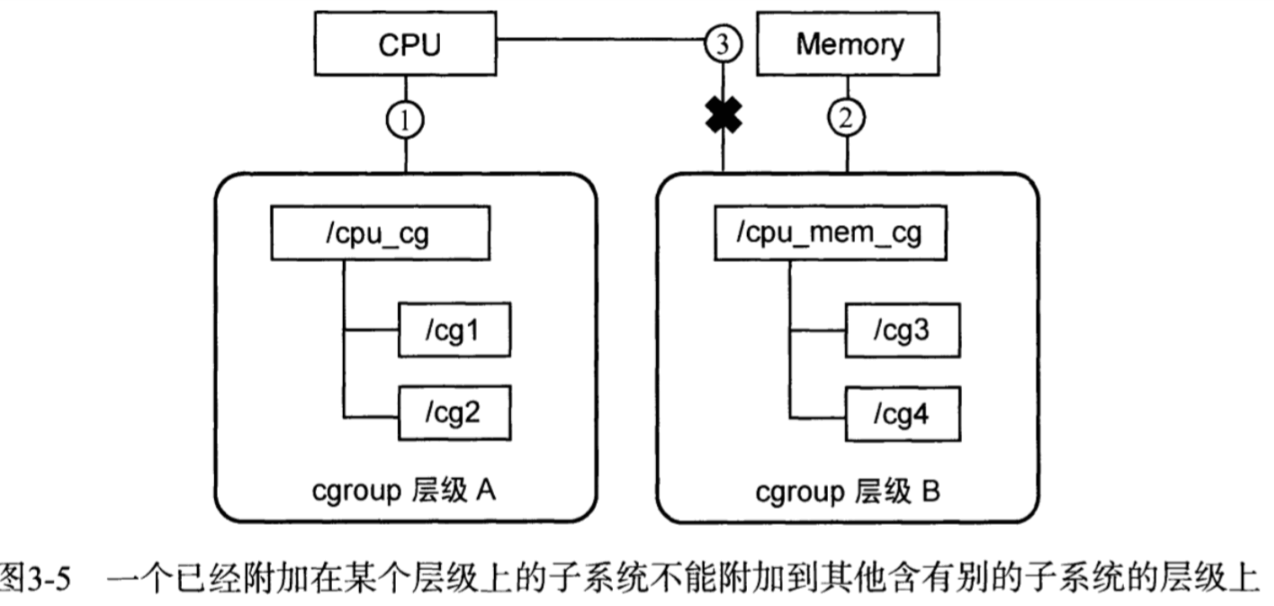
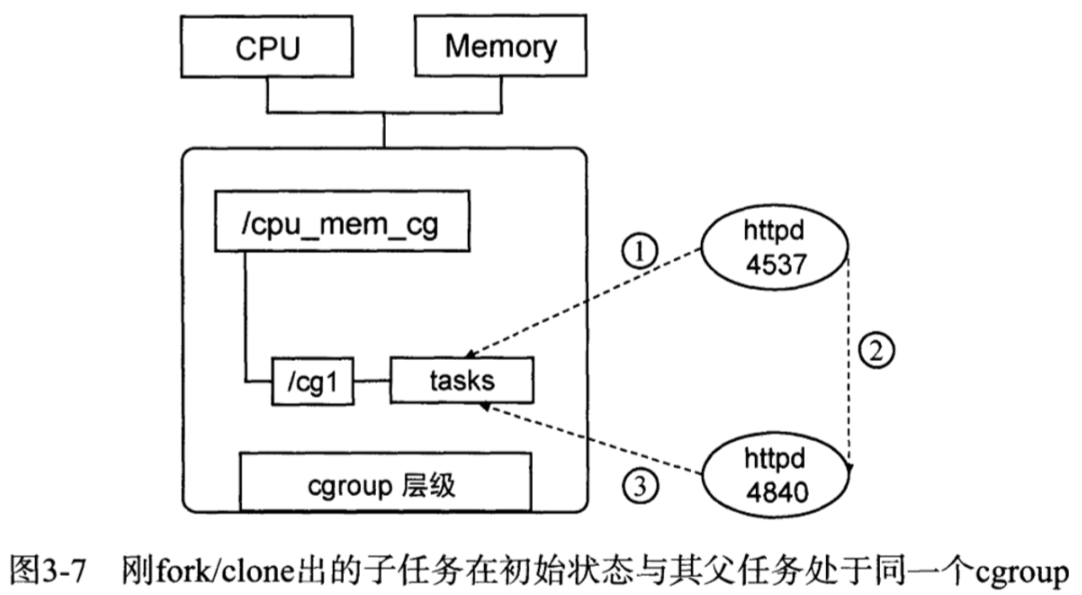
(3) 系统每次新建一个层级时,该系统上的所有任务默认加入这个新建层级的初始化cgroup,也称为root cgroup
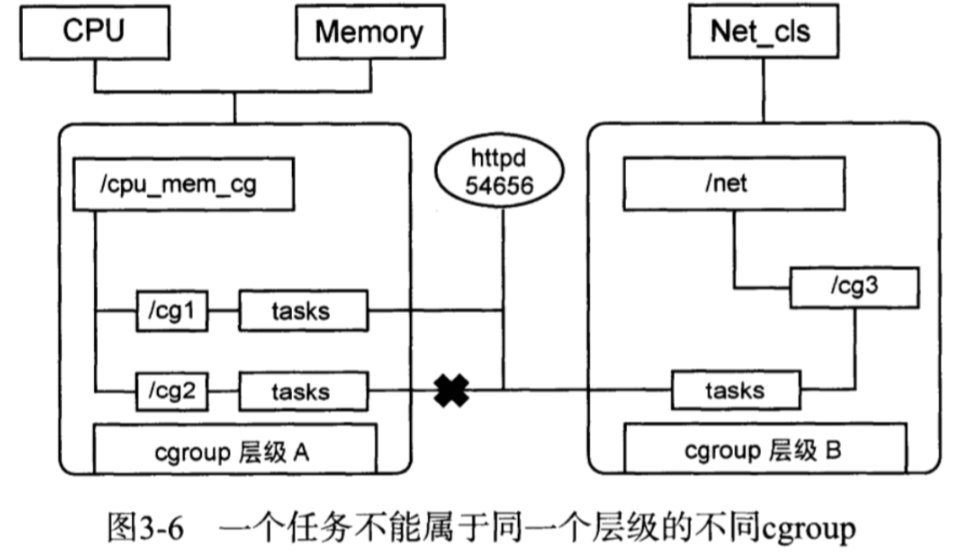
(4) 任务在fork/clone自身时,创建的子任务默认与原任务在同一个cgroup中,但子任务允许被移动到不同的cgroup中
子系统简介
cgroups的资源控制系统,每种子系统独立地控制一种资源。
目前Docker使用地9种子系统(暂未采用net_cls子系统):
- blkio:为块设备设定I/O限制
- cpu:使用调度程序控制任务对CPU地使用
- cpuacct:自动生成cgroup中任务对CPU资源使用情况的报告
- cpuset:为cgroup中任务分配独立的CPU和内存
- devices:开启或关闭cgroup中任务对设备的访问
- freezer:挂起或恢复cgroup中的任务
- memeory:设定cgroup中任务对内存使用量的限定,并自动生成任务对内存资源使用情况的报告
- perf_event:可以对cgroup中的任务进行统一的性能测试
- net_cls:未被Docker直接使用,它通过classid标记网络数据包,从而使Linux流量控制程序可以识别具体cgroup中生成的数据包
cgroups的实现方式及其工作原理
- cgroup如何判断资源超限及应对措施:使用统一的接口对资源进行控制和统计,超限后使用对应资源控制策略挂起任务或者结束任务
- cgroup与任务之间的关系:多对多,不直接关联,通过中间结构连接双向信息,每个任务中都可以查询到对应cgroup与各个子系统的情况
- Docker在使用cgroup时的注意事项:Docker通过挂载cgroup文件系统新建层级结构,并在挂载时指定绑定的子系统
- /sys/fs/cgroup/cpu/docker/
下文件的作用,tasks文件罗列cgroup中任务的所有进程或线程ID,cgroup.proc罗列cgroup中任务的线程组ID,notify_on_release包含0或1,表示cgroup中最后一个任务退出时,是否通知运行release agent,release_agent指定release agent执行脚本文件目录
3.2 Docker架构概览
Docker采用传统的CS模式,Docker Client与Docker Daemon间通信。
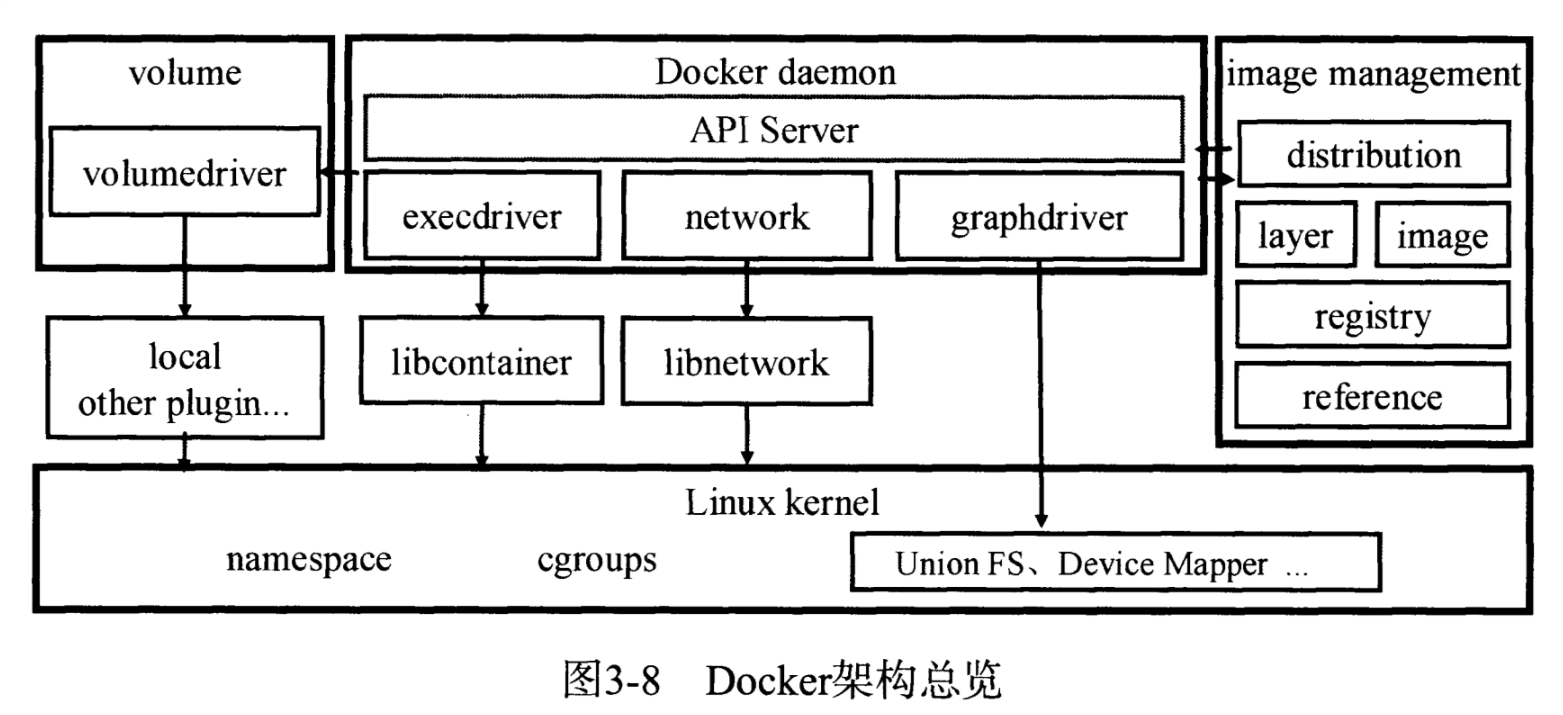
Docker Daemon
核心后台进程,负责响应来自Docker Client的请求,处理系统调用与容器管理,它会在后台启动一个API Server,接收到请求后分发调度执行
Docker Client
遵循Docker API的客户端,典型的如docker命令行工具
镜像管理
通过多个模块实现镜像管理,Docker 1.10版本以前由Graph组件完成
- distribution:与Docker registry交互,上传下载镜像以及存储与v2 registry有关的元数据
- registry:负责与Docker registry有关的身份验证、镜像查找、镜像管理以及管理registry mirror等
- image:负责与镜像元数据有关的存储、查找,镜像层得的索引、查找,以及镜像tar包有关的导入、导出
- reference:负责存储本地所有镜像的repository和tag名,并维护与镜像ID之间的映射关系
- layer:负责镜像层与容器层元数据有关的增删改查,并负责将镜像层的增删改查操作映射到存储实际镜像层文件系统的graphdriver模块
execdriver、volumedriver、graphdriver
作为相关系统调用抽象接口的实现,分为容器执行驱动、volume存储驱动、镜像存储驱动
- execdriver:对Linux操作系统namespaces、cgroups、apparmor、SELinux等容器运行所需系统操作的一层二次封装,目前的默认实现是官方的libcontainer,LXC也可以作为一种实现
- volumedriver:volume数据卷存储操作的最终执行者,负责volume的增删改查,屏蔽驱动实现为上层提供一个统一接口,默认实现是local,其他通过外部插件实现
- graphdriver:所有与容器镜像相关操作的最终执行者,在Docker工作目录下维护一组与镜像层对应的目录,并记下镜像层之间的关系以及与具体graphdriver实现相关的元数据,屏蔽掉不同文件存储实现对上层调用者的影响,具体实现有aufs、overlay、devicemapper等
network
Docker 1.9版本前通过networkdriver及libcontainer库完成,目前分离为独立的libnetwork库,它抽象出了一个容器网络模型(Container Network Model),并给调用者提供了一个统一接口,目标不仅限于Docker容器,CNM模型对真实容器网络抽象出了sandbox、endpoint、network等3种对象,由具体网络驱动操作对象,例如Bridge、Host、None、Overlay等,并通过一个网络控制器提供一个统一接口供调用者管理网络。
3.3 Client和Daemon
3.3.1 Client模式工作流程
(1)解析flag信息
(2)创建Client实例
(3)执行具体的命令:
- 从命令映射到对应的方法:反射机制,约定大于配置
- 执行对应的方法,发起请求:向Docker Daemon发送Client请求,读取响应
3.3.2 Daemon模式工作流程
API Server配置和初始化
根据配置参数创建负责处理用户请求的daemon对象
Daemon对象的创建与初始化
(1)Docker容器配置信息
供用户自由配置容器可选功能,配置信息的处理主要包含:
- 设置默认网络MTU
- 检测网桥配置信息
(2)检测系统支持及用户权限
- 操作系统支持:目前Docker Daemon只能运行在Linux上(Windows版本也有容器,还不稳定)
- root权限
- amd64架构及Linux内核3.10.0以上版本
(3)配置Daemon工作目录
默认 /var/lib/docker
(4)配置Docker容器所需文件环境
- 创建容器配置文件目录,默认 /var/lib/docker/containers,容器ID对应的文件夹下包含容器的所有元数据
- 配置graphdriver目录,例如 /var/lib/docker/aufs,加载并配置镜像存储驱动graphdriver,创建存储驱动管理镜像层文件系统所需的文件和目录,初始化镜像层元数据存储
- 配置镜像目录,默认 /var/lib/docker/images,存储所有镜像和镜像层管理数据
- 创建volume驱动目录,默认 /var/lib/docker/volumes,Docker种volume是宿主机挂载到Docker容器内部的特定目录
- 准备可信镜像所需工作目录,默认为 /var/lib/docker/trust,根据用户给出的可信URL加载授权文件,处理可信镜像的授权和验证过程
- 创建distributionMetadataStore与referenceStore用于存储镜像仓库列表
- 将持久化在Docker根目录中的镜像、镜像层及镜像仓库等元数据内容恢复到daemon的imageStore、layerStore和referenceStore中
- 执行镜像迁移

(5)创建Docker Daemon网络
libnetwork通过插件形式为Docker提供网络功能,默认驱动为bridge driver,适用于单机环境
(6)初始化execdriver
需要注意的5部分信息
- 运行指定驱动,默认为native,使用libcontainer
- 用户定义的execdriver选项,即-exec-opt参数
- 用户定义的-exec-root参数,Docker execdriver运行的root路径,默认 /var/run/docker
- Docker运行时的root路径,默认 /var/lib/docker
- 系统功能信息,包括容器的内存限制功能、交换区内存限制功能、数据转发功能以及AppArmor安全功能
(7)Daemon对象诞生
(8)恢复已有的Docker容器
3.3.3 从Client到Daemon
以docker run为例
- 发起请求
- 创建容器
- 启动容器
- execdriver与OS交互
3.4 libcontainer
到了3.4节,再回头看下,容器到底是什么?一个与宿主机系统共享内核,但与系统中的其他进程资源相隔离的执行环境,如何隔离?使用namespaces、cgoups、capabilities以及文件系统的管理和分配功能。
3.4.1 libcontainer的工作方式
execdriver根据Docker Daemon的提交信息创建了一份可供libcontainer使用的配置,从而创建真正的Docker容器,OCI组织成立后,lincontainer又进化为runC,从技术上讲,未来libcontainer/runC创建的将会是符合OCF标准的容器。这个阶段execdriver调用libcontainer执行了以下操作。
- 创建libcontainer构建容器所需的进程对象,Process,非真正的进程
- 设置容器的输出管道,这里使用的是Docker Daemon提供给libcontainer的pipes
- 使用Factory工厂类,创建逻辑容器Container,包含容器ID、容器配置
- 执行Container.Start(Process)启动物理容器
- execdriver执行由Docker Daemon提供的startCallback完成回调动作
- execdriver执行Process.Wait,一直等待上述Process的所有工作完成
3.4.2 libcontainer实现原理
(1)用Factory创建逻辑容器Container
- 验证容器运行根目录(默认/var/lib/docker/containers)、容器ID、容器配置
- 验证上述容器ID与现有容器不冲突
- 在根目录下创建ID为名的容器工作目录(/var/lib/docker/containers/{容器ID})
- 返回一个Container对象,包含容器ID、容器工作目录、容器配置、初始化指令与参数(即dockerinit),以及cgroups管理器(通过文件操作管理或systemd管理)
(2)启动逻辑容器Container
参与容器创建过程的Process共有两个实例
- Process,用于物理容器内进程的配置和IO的管理
- ParentProcess,负责从容器外部处理物理容器启动工作,与Container对象直接交互
Container的Start()启动过程主要有两个工作,创建ParentProcess实例,然后执行ParentProcess.start()来启动物理容器
创建ParentProcess的过程如下
- 创建一个管道用来与容器内要运行的进程通信
- 根据逻辑容器Container中与容器内要运行的进程相关信息创建一个容器内进程启动cmd对象,由os/exec包声明,Docker根据它创建容器中的第一个进程dockerinit
- 为cmd添加环境变量_LIBCONTAINER_INITTYPE=standard来告诉将来的容器进程(dockerinit)当前执行的是“创建”动作。
- 将容器需要配置的namespace添加到cmd的Cloneflags中,表示将来这个cmd要运行在上述namespace中
- 将Container中的容器配置和Process中的EntryPoint信息合并为一份容器配置加入到ParentProcess中
(3)用逻辑容器创建物理容器
- Docker Daemon用exec包执行initProcess.cmd,效果等价于创建一个新的进程并为它设置namespace,dockerinit进程所在的namespace即为用户最终的Docker容器指定的namespace
- 把容器进程dockerinit的PID加入到cgroup中管理
- 创建容器内部的网络设备,包括lo和veth
- 通过管道发送容器配置给容器内进程dockerinit
- 通过管道等待dockerinit根据上述配置完成的所有初始化工作,或者出错返回
综上所述,ParentProcess启动了一个子进程dockerinit作为容器内的初始进程,并作为父进程通过pipe在容器外对dockerinit管理和维护。
dockerinit进程在容器内部的初始化工作如下
- 创建pip管道所需的文件描述符
- 通过管道获取ParentProcess传来的容器配置,如namespace、网络等信息
- 从配置信息中获取并设置容器内的环境变量
- 若用户在docker run中指定来-ipc、-pid、-uts参数,则dockerinit还需要将自己加入到用户指定的上述namespace中
- 初始化网络设备(ParentProcess中创建的lo和veth),初始化工作包括:修改名称、分配MAC地址、设置MTU、添加IP地址和默认网关等
- 设置路由和RLIMIT参数
- 创建mount namespace,为挂载文件系统做准备
- 在上述mount namespace中设置挂载点,挂载rootfs和各类文件设备,例如/proc,然后通过pivot_root切换进程根路径到rootfs的根路径
- 写入hostname等,加载profile信息
- 比较当前进程的父进程ID与初始化进程一开始记录下来的父进程ID,若不同,则说明父进程异常退出过,终止初始化,否则执行最后一步
- 使用execv系统调用执行容器配置中的Args指定的命令,即EntryPoint和docker run的[COMMAND]参数
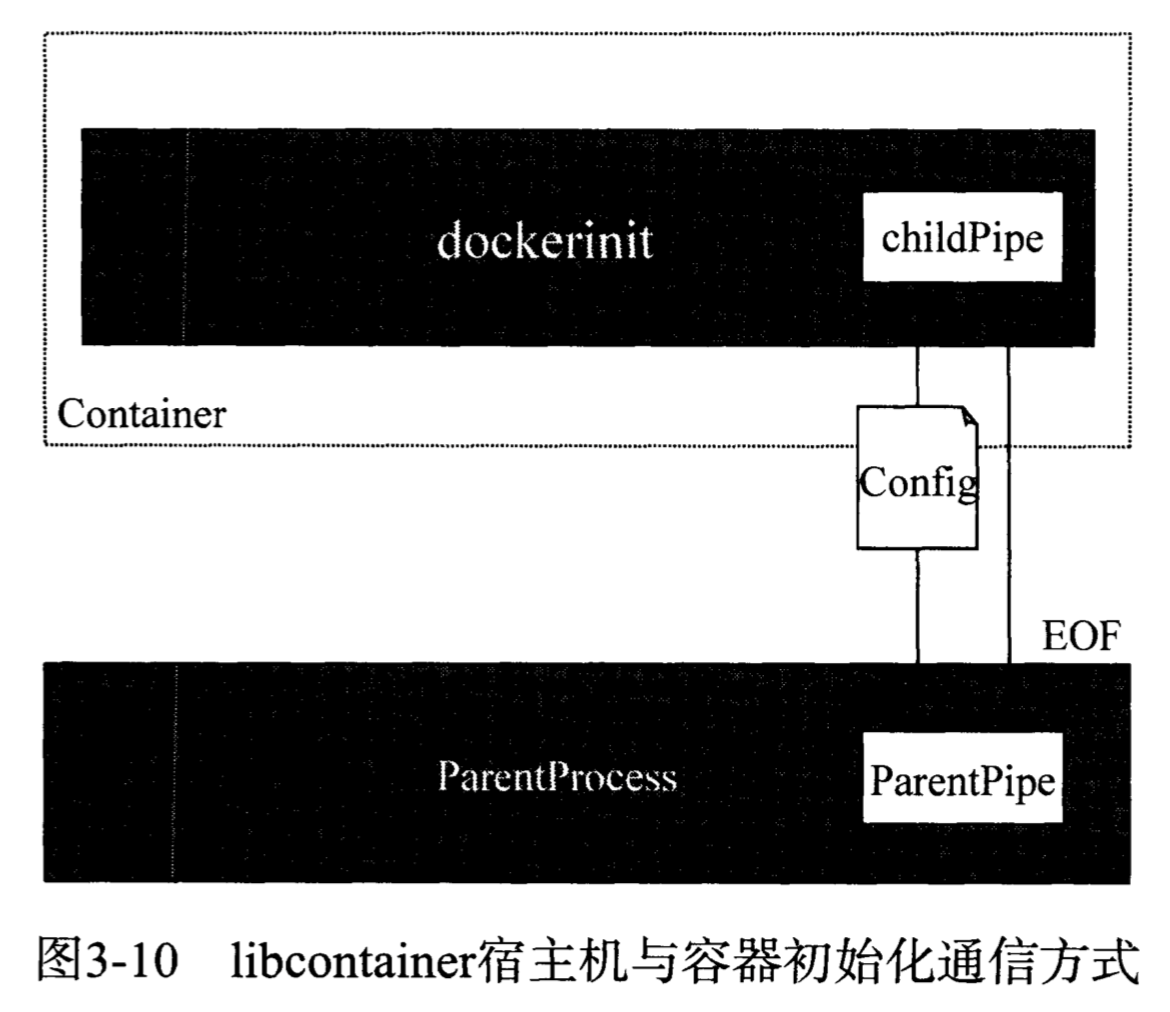
(4)Docker Daemon与容器之间的通信方式
上述容器进程启动后的初始化操作,使用来namespace隔离后的两个进程间的通信,父进程克隆出子进程后,依旧共享内存,如何让子进程感知内存中写入来新数据,一般有以下4种方法
- 发送信号通知(signal):signal本身包含的信息有限,需要额外记录,namespace带来的上下文变化使其操作更为复杂
- 对内存轮询访问(poll memory):低效
- sockets通信(sockets):Docker会加入network namespace,初始时网络栈完全隔离,不可行
- 文件和文件描述符(files and file-descriptors):Docker最终选择的方式,管道
在Linux中通过pipe(int fd[2])系统调用创建管道,参数是包含两个整型的数组,创建的子进程会内嵌这个打开的文件描述符,调用后在fd[1]端写入的数据可以从fd[0]读取,通过管道,父子进程之间就可以通信。这个通信完成的标志就在于EOF信号的传递,当父进程通过pipe向子进程发送完毕初始化所需信息后,先关闭自己这一端的管道,然后等待子进程关闭另一端的管道文件描述符,传来EOF表示子进程已完成初始化工作。
3.5 Docker镜像管理
3.5.1 什么是Docker镜像
Docker镜像是一个只读的Docker容器模版,含有启动Docker容器所需的文件系统结构及其内容,可以说Docker镜像是Docker容器的静态视角,Docker容器是Docker镜像的运行状态
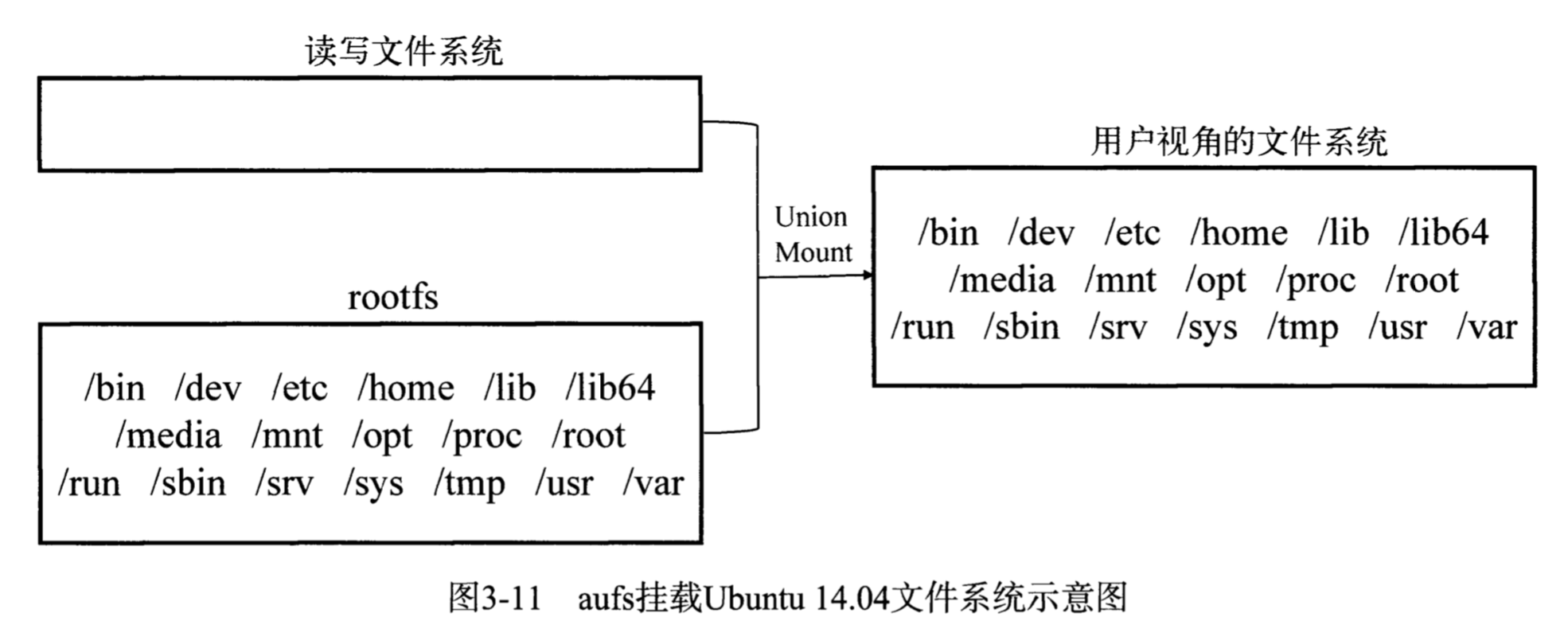
(1)rootfs
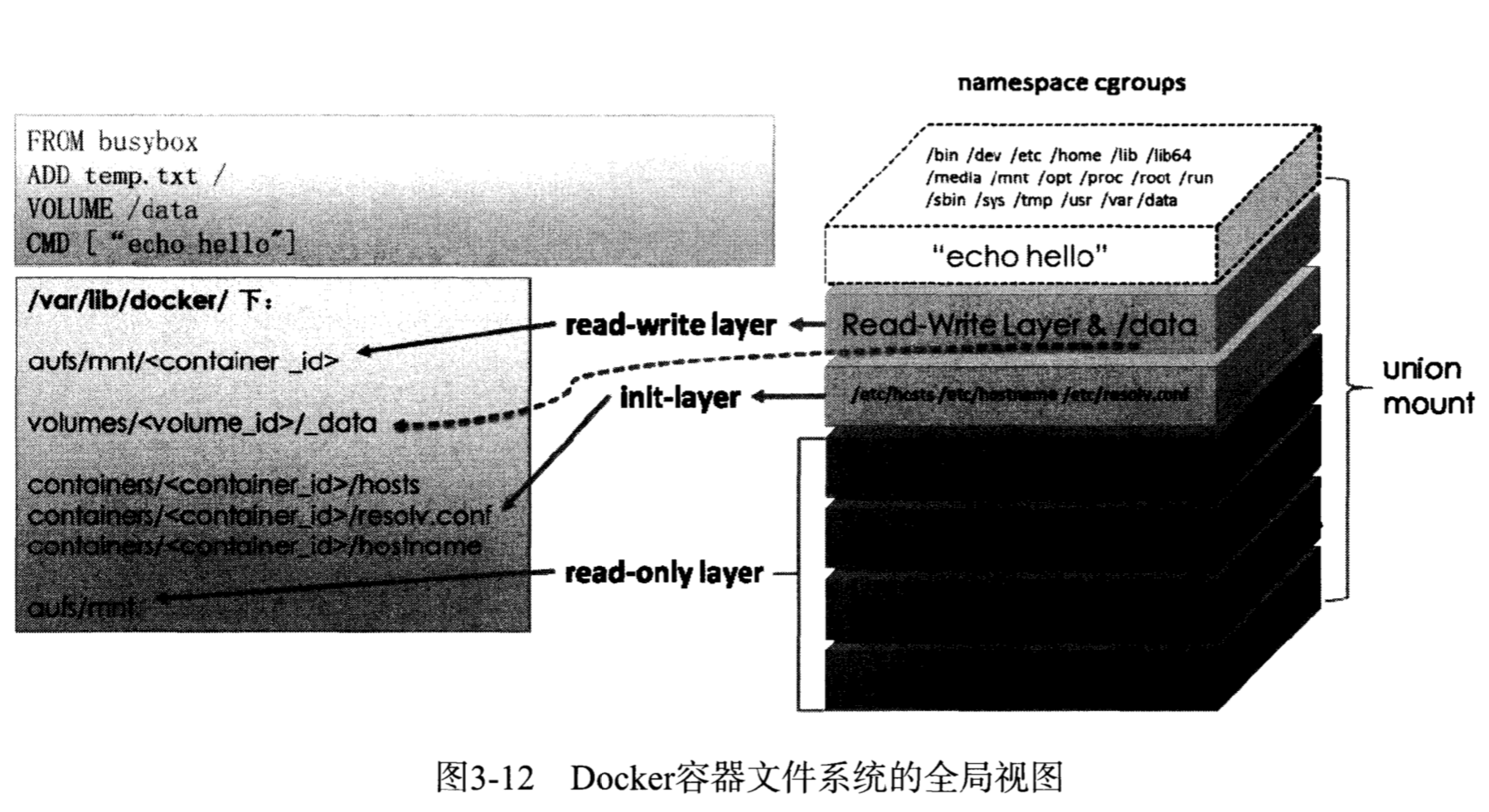
rootfs是Docker容器在启动时内部进程可见的文件系统,Docker容器的根目录,通常包含一个操作系统运行所需的文件系统。传统Linux操作系统内核启动时,先挂载一个只读的rootfs,系统检测其完整性后,再将其切换为读写模式,Docker Daemon为Docker容器挂载rootfs时,沿用了Linux内核启动时的方法,挂载完毕后,利用联合挂载技术在已有的只读rootfs上再挂载一个读写层。读写层处于Docker容器文件系统的最顶层,其下可能联合挂载多个只读层,在运行过程中文件系统发生变化时,把变化的文件内容写到可读层,并隐藏读写层中的老版本文件。
(2)Docker镜像的主要特点
- 分层:采用分层方式构建,每个镜像都是由一系列的“镜像层”组成
- 写时复制(copy-on-write):每个容器启动时并不需要单独复制一份镜像文件,而是将所有镜像层以只读方式挂载到一个挂载点,再在上面覆盖一个可读写的容器层。写时复制配合分层机制减少了对磁盘空间的占用和容器启动时间。
- 内容寻址(content-addressable storage):根据文件内容来索引镜像和镜像层,与之前对每个镜像层随机生成一个UUID不同,新模型对镜像层的内容计算校验和,生成一个内容哈希值,并以此代替之前的UUID作为镜像层的唯一标志。该机制主要提高来镜像的安全性,并在pull、push、load和save操作后检测数据的完整性,另外一定程度上减少来ID的冲突并增强来镜像层的共享。
- 联合挂载:可以在一个挂载点同时挂载多个文件系统,将挂载点的原目录与被挂载内容进行整合,使得最终可见的文件系统将会包含整合后的各层文件和目录,实现这种技术的文件系统通常被称为联合文件系统(union filesystem)。联合挂载是下层存储驱动(aufs、overlay等)实现分层合并的方式,但并不是Docker镜像的必须技术,例如Device Mapper存储驱动使用快照技术达到分层的效果,并没有联合挂载的概念
(3)Docker镜像的存储组织方式
3.5.2 Docker镜像关键概念
(1)registry
用以保存Docker镜像,包括镜像层次结构和关于镜像的元数据,相当于Docker的Git仓库,例如Docker Hub
(2)repository
具有某个功能的Docker镜像的所有迭代版本构成的镜像组,例如ansible/ubuntu14.04-ansible,registry由一系列经过命名的repository组成,repository通过命名规范对用户仓库和顶层仓库进行组织
(3)manifest
描述文件,存在于registry中作为Docker镜像的元数据文件,在pull、push、save和load中作为镜像结构和基础信息的描述文件,在镜像被pull或者load到Docker宿主机时,manifest被转化为本地的镜像配置文件config
(4)image和layer
image用来存储一组镜像相关的元数据信息,主要包括镜像架构、镜像默认配置、构建镜像的容器配置信息、包含所有镜像层信息的rootfs。Docker利用rootfs中的diff_id计算出内容寻址的索引(chainID)来获取layer相关信息,进而获取每一个镜像层的文件内容。
layer时一个Docker用来管理镜像层的中间概念,单个layer可能被多个镜像共享。layer主要存放了镜像层的diff_id、size、cache-id和parent等内容,实际文件内容由存储驱动管理,并可通过cache-id在本地索引到。
(5)Dockerfile
docker build命令构建镜像时需要使用的定义文件,允许用户使用基本的DSL语法来定义Docker镜像,每一条指令描述了构建镜像的步骤
3.5.3 Docker镜像的构建操作
(1)commit镜像
docker commit将容器提交为一个镜像,只提交发生变更的部分,即修改后的容器镜像与当前仓库中对应镜像之间的差异部分,步骤如下
- 根据用户输入pause参数确定是否需要暂停容器运行
- 将容器可读写层导出打包
- 在层存储中注册可读写层差异包
- 更新镜像历史信息和rootfs,并据此在镜像存储中创建一个新的镜像,记录元数据
- 若指定了repository,则为该镜像添加tag信息
(2)build构建镜像
- Docker Client:解析命令行参数,根据第一个参数的不同,分为从命令行读取参数、从URL克隆git repo、从URL下载、本地文件或目录构建context,将context传递给Docker Server
- Docker Daemon:接收Client传递的context,创建临时目录存储context内容,读取解析Dockerfile,其中的每一个指令都会生成一个镜像层,此次build的结果就是这些镜像层的集合,若指定了tag,则会给镜像打上对应tag,最后一次commit生成的镜像ID会作为最终的镜像ID返回
3.5.4 Docker镜像的分发方法
Docker技术兴起的原动力之一,是在不同的机器上创造无差别的应用运行环境。由于容器与镜像的天然联系性,我们可以直接导出容器,也可以通过镜像分发的方式达成,直接对容器进行持久化和使用镜像进行持久化的区别如下
- docker export用于持久化容器,docker push和docker save用于持久化镜像
- 将容器导出后再导入(exported-imported)的容器会丢失所有的历史,而保存后再加载(saved-loaded)的镜像则不会丢失历史和层,这也意味着后者可以通过docker tag命令实现历史层回滚,而前者不行
Docker Daemon端实现角度的pull、push、export以及save
(1)pull镜像
- 根据用户命令行参数解析出repository信息
- 将repository信息解析为RepositoryInfo并验证其合法性
- 根据待拉取的repository是否为official版本及用户是否配置Docker Mirrors获取endpoint列表,遍历列表并向该endpoint指定的registry发起会话
- 由endpoint和待拉取镜像名创建HTTP会话、获取指定镜像的认证信息并验证API版本
- 若tag值为空,且没有指定下载所有tag镜像的flag,-a,则默认拉取latest标签的镜像,否则获取registry中repository的tag list中的每一个标签拉取,该功能分成两大部分,验证用户请求与拉取不在本地的镜像层
- 若tag值不为空,则只拉取指定标签的镜像
(2)push镜像
- 解析repository信息
- 获取所有非Docker Mirrors的endpoint列表,并验证repository在本地是否存在。遍历endpoint,然后发起通registry的会话
- 验证被推registry的访问权限,创建V2Pusher,调用pushV2Repository方法。若用户输入的repository名字含有tag,则从本地repository中获取对应镜像的ID,调用pushV2Tag方法,若不含tag,则在本地repository中查询所有同名repository,对其中每一个获取镜像ID,执行pushV2Tag方法
- pushV2Tag方法首先验证用户指定的镜像ID在本地ImageStore中是否存在。然后对其从顶向下逐个构建一个描述结构体,上传这些镜像层,上传完毕后再将一份描述文件manifest上传到registry
(3)docker export导出容器
- 根据命令行参数(容器名称)找到待导出容器
- 对该容器调用containerExport()函数导出容器中的所有数据,包括:挂载待导出容器的文件系统、打包该容器的basefs(即graphdriver上的挂载点)下的所有文件、返回打包文档的结果并卸载该容器的文件系统
- 将导出的数据回写到HTTP请求应答中
(4)docker save保存镜像
根据镜像ID在imageStore中获取image结构体,其次是一个for循环遍历镜像rootfs中的所有layer,对各个依赖进行export工作,按即从顶层layer、父layer直至base layer,循环内工作如下
- 为每个被要求导出的镜像创建文件夹,以镜像ID命名
- 在文件夹下创建VERSION文件,写入“1.0”
- 在文件夹下创建json文件,写入镜像元数据信息,包括镜像ID、父镜像ID及其对应的Docker容器ID等
- 在文件夹下创建layer.tar文件,压缩镜像的filesystem
- 对该layer的父layer执行下一次循环
3.6 Docker存储管理
3.6.1 Docker镜像元数据管理
Docker镜像在设计上将镜像元数据与镜像文件的存储完全隔离开,管理镜像层元数据时,采用的是从上至下repository、image、layer三个层次,由于Docker以分层的形式存储镜像,所以repository和image这两类元数据并无物理上的镜像文件与之对应,而layer这种元数据则存在物理上的镜像层文件与之对应。
(1)repository元数据
repository是具有由某个功能的Docker镜像的所有迭代版本构成的镜像库,它在本地的持久化文件存放于 /var/lib/docker/image/some_graph_driver/repositories.json 中,结构如下
1cat repositories.json|python -mjson.tool
2{
3 "Repositories": {
4 "docker.io/postgres": {
5 "docker.io/postgres:10": "sha256:084ec18124c8ccb08c7df98492db211f19a6a3d9e159cc88d1281c634b90bb87",
6 "docker.io/postgres@sha256:1d26fae6c056760ed5aa5bb5d65d155848f48046ae8cd95c5b26ea7ceabb37ad": "sha256:084ec18124c8ccb08c7df98492db211f19a6a3d9e159cc88d1281c634b90bb87"
7 },
8 "docker.io/redis": {
9 "docker.io/redis:4": "sha256:e1a73233e3beffea70442fc2cfae2c2bab0f657c3eebb3bdec1e84b6cc778b75",
10 "docker.io/redis@sha256:b77926b30ca2f126431e4c2055efcf2891ebd4b4c4a86a53cf85ec3d4c98a4c9": "sha256:e1a73233e3beffea70442fc2cfae2c2bab0f657c3eebb3bdec1e84b6cc778b75"
11 }
12}
文件中存储了所有repository的名字及其所有版本镜像的名字和tag、tag对应的镜像ID。而referenceStore的作用便是解析不同格式的repository名字,并管理repository与镜像ID的映射关系
(2)image元数据
image元数据包括了镜像架构、操作系统、镜像默认配置、构建该镜像的容器ID和配置、创建时间、创建该镜像的Docker版本、构建镜像的历史信息以及rootfs组成(可以根据历史信息和rootfs中的diff_ids计算出构成该镜像的镜像层存储索引ID)。
imageStore管理镜像ID与镜像元数据之间的映射关系以及元数据的持久化操作,持久化文件位于 /var/lib/docker/image/{graph_driver}/imagedb/content/sha256/{image_id},以json形式存储
(3)layer元数据
layer对应镜像层的概念,用户在Docker宿主级上下载了某个镜像层后,Docker会基于镜像层文件和image元数据构建本地layer元数据,包括diff、parent、size等,而上传镜像层到regitsry时,元数据并不会一起打包上传。
Docker中定义了Layer与RWLayer两种接口,分别用来定义只读层和可读写层的一些操作,又定义了roLayer和mountedLayer,分别实现了上述两种接口,对应不可变的镜像层与可读写的容器层。
roLayer主要存储了索引该镜像层的chainID、该镜像层的校验码diffID、父镜像层parent、graphdriver存储当前镜像层文件的cacheID、镜像层的大小size等,数据持久化文件位 /var/lib/docker/image/{graph_driver}/layerdb/sha256/{chainID} 文件夹下,其中
- diffID与size可通过该镜像层包计算出,diffID采用SHA256算法
- chainID与父镜像层parent需要从所属image元数据中计算得到,chainID是基于内容存储的索引,根据当前层与所有祖先镜像层diffID计算得出,若该镜像层是最底层(无父镜像层),该层diffID便是chainID,否则chainID(n)=SHA256(chain(n-1) diffID(n)),也就是根据父镜像层chainID加上一个空格和当前层的diffID,再计算SHA256校验码
- cacheID是在当前Docker宿主机上随机生成的一个uuid,在宿主机上与该镜像层一一对应,用于标示并索引graphdriver中的镜像层文件
mountedLayer主要存储了为索引某个容器可读写层的ID(对应容器ID)、容器init层在graphdriver中的ID-initID、读写层在graphdriver中的ID-mountID、容器的父镜像层chainID-parent。持久化文件位于 /var/lib/docker/image/{graph_driver}/layerdb/mounts/{container_id} 文件夹下
3.6.2 Docker存储驱动
存储驱动根据操作系统底层的支持提供了针对某种文件系统的初始化操作和对镜像层的增删改查与差异比较等操作。目前存储系统的接口已有aufs、btrfs、devicemapper、vfs、overlay、zfs等6种具体实现,其中vfs不支持写时复制,是为使用volume提供的存储驱动,仅仅做了简单的文件挂载操作。
1. 存储驱动的功能与管理
Dcoker中管理文件系统的驱动graphdriver定义了统一的接口对不同的文件系统进行管理,在Docker Daemon启动时根据不同的文件系统选择合适的驱动
(1)存储驱动接口定义
GraphDriver中主要定义了Driver与ProtoDriver两个接口,所有存储驱动通过实现Driver的12个接口提供相应的功能,而ProtoDriver定义了其中的8个基本功能接口实现增删改查,正常的Driver接口实现通过包含一个ProtoDriver的匿名对象实现,还定义了其他4个方法用于对数据层之间的差异进行管理。GraphDriver提供的naiveDiffDriver结构就包含了一个ProtoDriver对象并实现了Driver接口中与差异有关的方法,可以看作Driver的一个实现。
只要集成了基本存储操作和差异操作的实现,一个存储驱动就算开发完成了。
(2)存储驱动的创建过程
各类存储驱动都需要定一个属于自己的初始化过程,并且在初始化过程中向GraphDriver注册自己,GraphDriver根据存储驱动名从drivers列表中查找对应初始化方法,调用后得到对应的Driver对象。创建驱动时首先检查环境变量DOCKER_DRIVER与DefaultDriver(daemon启动时的-storage-driver或-s参数),尝试获取合法驱动名并创建Driver对象实体,若两者为空,则从驱动优先级列表中查找一个可用(驱动曾注册过、驱动对应文件系统被操作系统支持)的驱动,Linux下的优先级列表依次包含:aufs、btrfs、zfs、devicemapper、overlay和vfs,若仍旧找不到可用驱动,则使用第一个注册过且可用的驱动返回
2. 常用存储驱动
(1)aufs(advanced multi layered unification filesystem)
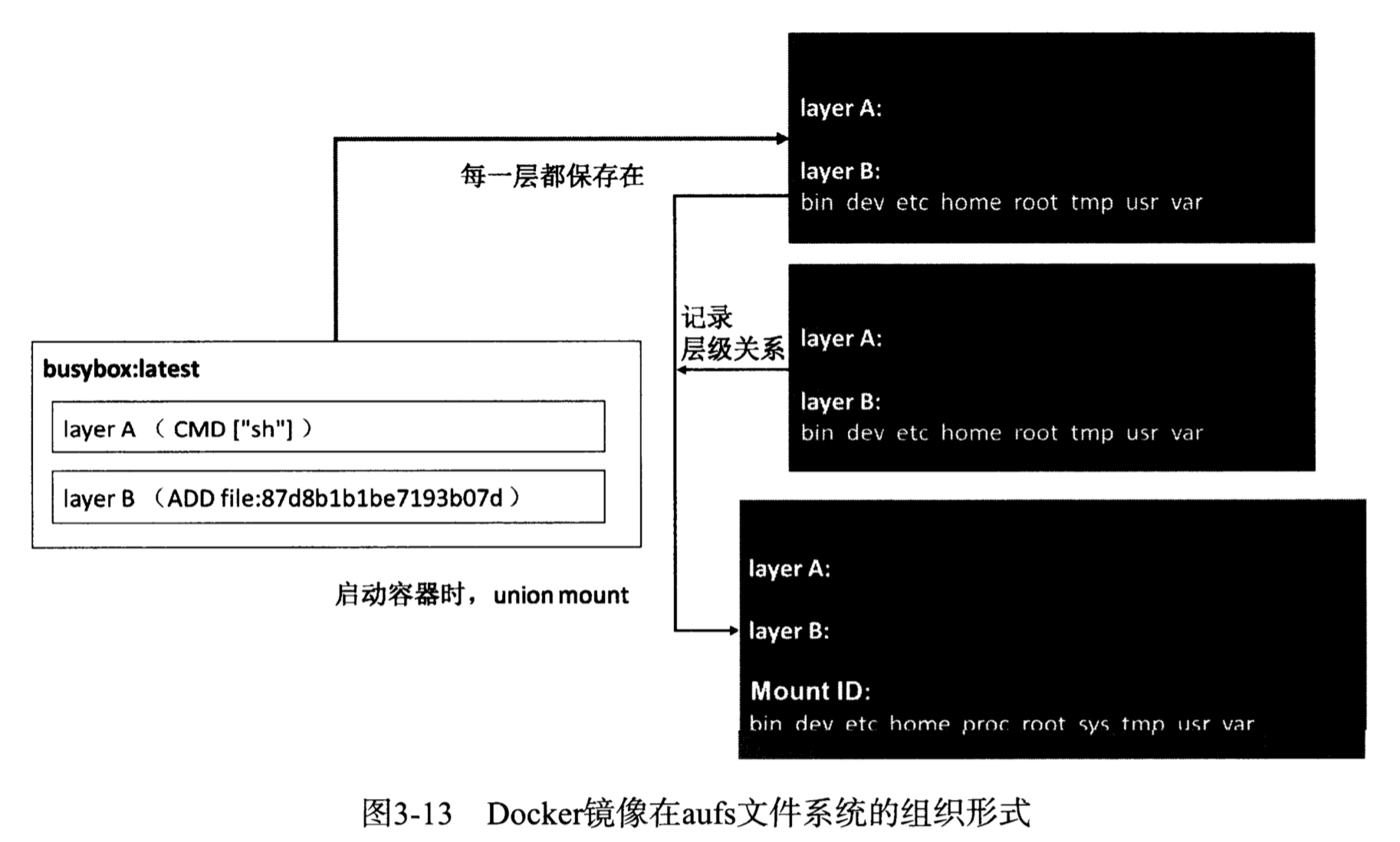
aufs是一种支持联合挂载的文件系统,可以将不同目录挂载到同一个目录下,挂载操作对用户透明。这些目录的挂载是分层次的,通常最上层为读写层,下层为只读层,aufs的每一层都是一个普通文件系统。
- 读取文件:从最顶层的读写层开始往下找,若本层没有,则根据层之间的关系到下一层找,直到找到第一个文件并打开它
- 写入文件:若文件不存在,则在读写层新建一个,否则执行读取文件的策略,找到最近的文件,将它复制到读写层进行修改(第一次修改某文件,且文件很大时,会产生巨大磁盘开销)
- 删除文件:若文件只存在于读写层,则直接删除,否则先删除它在读写层中的备份,再在读写层中创建一个whiteout文件来标记这个文件不存在,而不是真正删除底层文件
- 新建文件:若文件在读写层存在对应whieout文件,则先删除它再新建文件,否则直接在读写层新建即可
镜像文件存放在 /var/lib/docker/aufs,目录下有三个文件夹
- diff:实际的数据来源,包括只读层和可读写层,所有这些层最终一起被挂载在mnt上的目录
- layers:与每层依赖有关的层描述文件
- mnt:aufs的挂载目录
创建一个新镜像层的步骤如下
- 分别在mnt和diff目录下创建与该层的mountID同名的子文件夹
- 在layers目录下创建与该层的mountID同名文件,用来记录该层所依赖的所有其他层
- 若参数中的parent项不为空(创建容器时parent就是镜像最上层),说明该层依赖于其他层,GraphDriver就将parent的mountID写入到该层在layers下对应mountID的文件里,然后GraphDriver还需要在layers目录下读取与上述parent同mountID的文件,将parent层的所有依赖也复制到这个新创建层对应的层描述文件中,这样该文件才记录了该层的所有依赖

随后GraphDriver将diff中属于容器镜像的所有层目录以只读形式挂载到mnt下,然后在diff中生成一个以当前容器对应的

这些文件与容器内环境相关但又不适合被打包作为镜像的文件内容,于是Docker容器文件存储中设计了mountID-init层,只在容器启动时添加,根据系统环境和用户配置自动生成具体的内容,只有这些文件在运行过程被改动且docker commit了才会持久化这些变化,否则保存镜像时不会包含这一层的内容。所以严格上讲,除了可读写层、只读层外,Docker容器的文件系统应该还包含init层,但它对用户来说完全透明。
接下来会在diff中生成一个以容器对应mouontID为名的可读写目录,也挂载到mnt目录下,将来用户在容器中新建文件出现在这个目录下,而该层对应的实际内容则保存在diff目录下。
(2)devicemapper
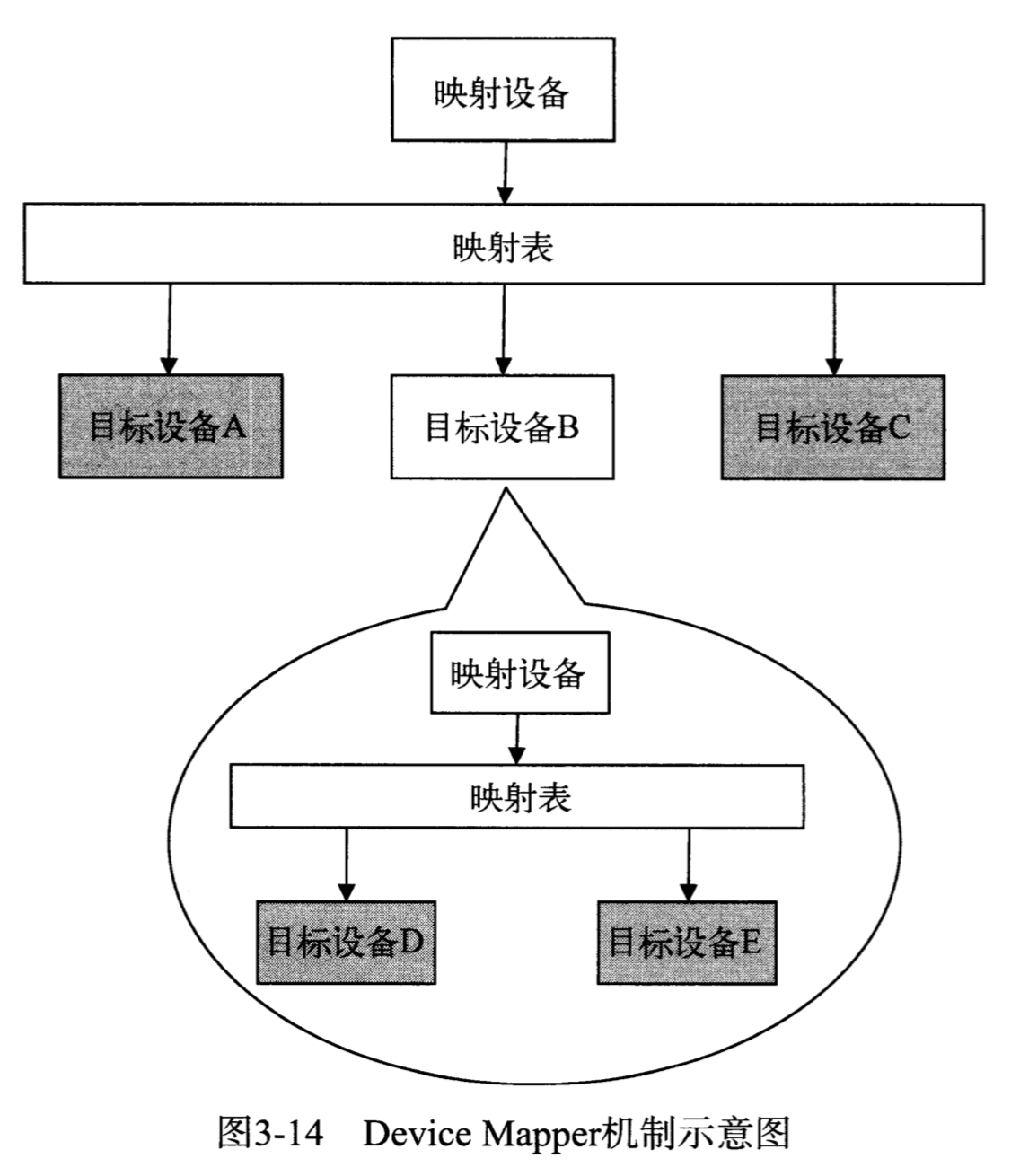
Device Mapper是Linux2.6内核中提供的一种从逻辑设备到物理设备的映射框架机制,用户可以根据自己的需要定制实现存储资源的管理策略。
Device Mapper的三个概念
- 映射设备:内核向外提供的逻辑设备,一个映射设备通过一个映射表与多个目标设备映射起来,一个映射设备最终通过一颗映射树映射到物理设备上
- 映射表:映射表包含多个多元组,每个多元组记录了这个映射设备的其实地址、范围与一个目标设备的地址偏移量的映射关系
- 目标设备:目标设备可以是一个物理设备,也可以是一个映射设备,这个映射设备可以继续向下迭代
Device Mapper的本质功能是根据映射关系描述IO处理规则,当映射设备接收到IO请求的时候,这个IO请求会根据映射表逐级转发,直到请求最终传到最底层的物理设备上
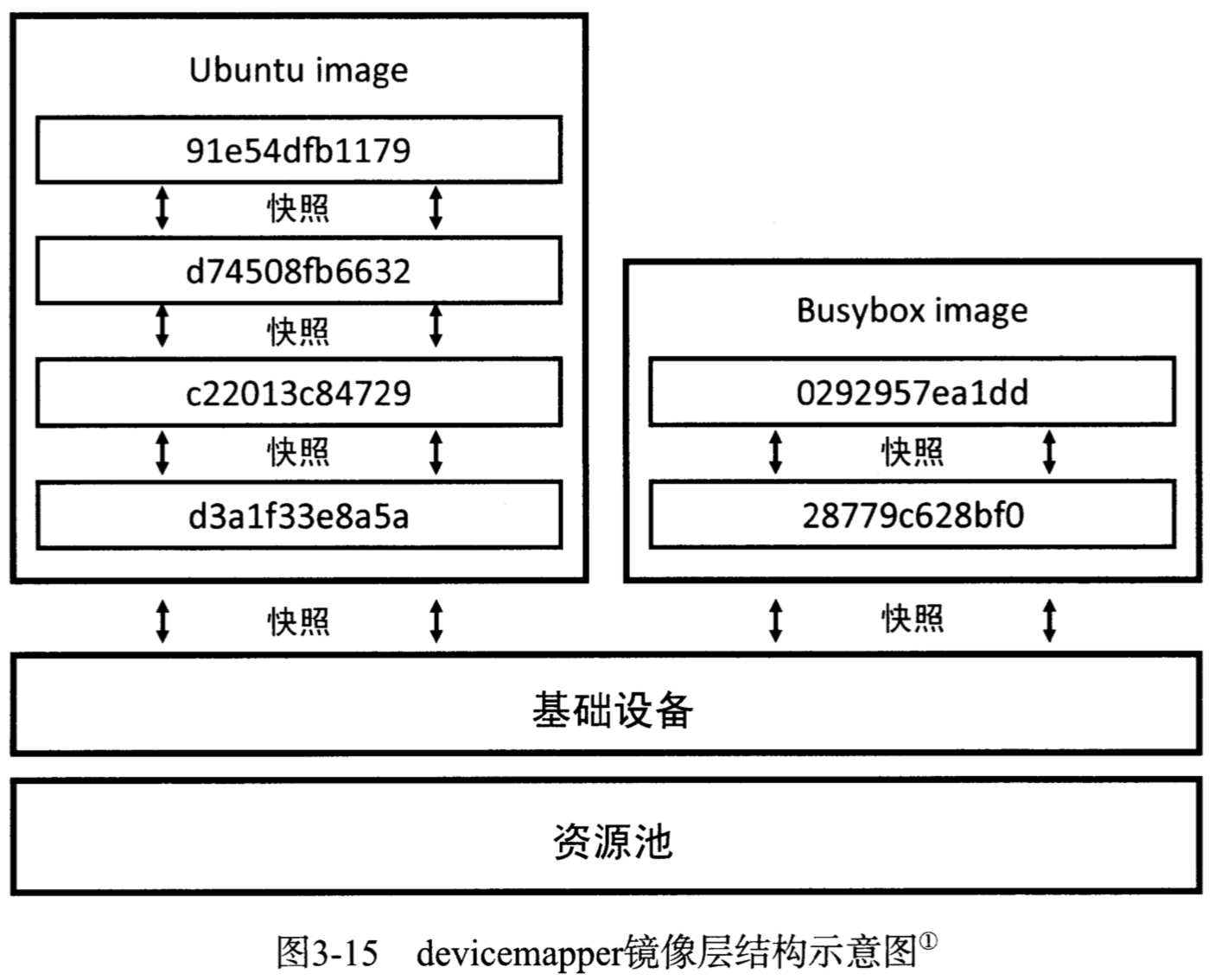
Docker下的devicemapper存储驱动使用Device Mapper的精简配置(thin-provisioning)和快照(snapshotting)实现镜像的分层。这个模块使用了两个块设备(一个用于存储数据,另一个用于存储元数据),并将其构建成一个资源池用以创建其他存储镜像的块设备,数据区为生成其他块设备提供资源,元信息存储了虚拟设备和物理设备的映射关系,写时复制发生在块存储级别。
devicemapper在构建一个资源池后,会先创建一个有文件系统的基础设备,再从已有设备创建快照的方式创建新的设备,这些新创建的块设备在写入内容前并不会分配资源。所有的容器层和镜像层都有自己的块设备,均通过从父镜像层创建快照的方式来创建。
devicemapper存储驱动根据使用的两个基础块设备是真正的块设备还是稀疏文件挂载的loop设备氛围两种模式,前者称为direct-lvm模式,后者则是Docker默认的loop-lvm模式,两种模式对用户透明,但由于底层存储方式不同导致两者性能差异很大,由于loop-lvm不需要额外配置的易用性,Docker将其作为devicemapper的默认模式,生产环境中推荐使用direct-lvm模式。
若使用devicemapper驱动,/var/lib/docker 下会创建 image/devicemapper 以及 devicemapper 目录,前者存储镜像和逻辑镜像层的元数据,后者存储具体文件,在文件下有三个子目录,mnt为设备挂载目录,devicemapper下存储loop-lvm模式下的两个稀疏文件,metadata下存储了每个块设备驱动层的元数据信息
在loop-lvm模式下,devicemapper下data文件是一个100GB的稀疏文件,包含所有镜像和容器的实际文件内容,是整个资源池的默认大小,每个容器默认被限制在10GB大小的卷内。
(3)overlay
OverlayFS是一种新型联合文件系统,它允许用户将一个文件系统与另一个文件系统重叠,在上层的文件系统中记录更改,而下层的文件系统保持不变。相比aufs,OverlayFS在设计上更简单,理论上性能更好,docker的overlay驱动便建立在OverlayFS基础上。
OverlayFS主要使用4类目录来完成工作,被联合挂载的两个目录lower和upper,作为统一视图联合挂载点的merged目录,还有作为辅助功能的work目录。作为upper和lower被联合挂载的统一视图,当同一路径的两个文件分别存在两个目录中时,位于上层目录upper中的文件会屏蔽位于下层lower中的文件,若是同路径的文件夹,下层目录中的文件和文件夹会被合并到上层。在对可读写的OverlayFS挂载目录中的文件进行读写删等操作与挂载两层aufs类似,但需要注意的是,第一次以写方向打开一个位于下层目录的文件时,OverlayFS会执行一个copy_up将文件从下层复制到上层,与aufs不同的是,这个copy_up的实现不符合POSIX标准。
书本内容与overlay2驱动已经有较多差异,略过这部分