读书笔记-Docker容器与容器云(第2版)-03
文章目录
数据卷以及网络是平时手动运行容器或者用docker-compose部署时最常交互的部分,这里独立记录一下。
3.7 数据卷
Docker镜像的分层存在的问题
- 容器中的文件在宿主机上存在形式复杂,不能在宿主机上方便地对容器中的文件进行访问
- 多个容器间的数据无法共享
- 删除容器时,容器产生的数据将丢失
Docker引入数据卷机制,volume是存在于一个或多个容器中的特定文件或文件夹,该目录以独立于联合文件系统的形式在宿主机中存在
- volume在容器创建时就会初始化,容器运行时可以使用其中的文件
- volume能在不同的容器之间共享和重用
- 对volume中数据的操作会马上生效
- 对volume中数据的操作不影响到镜像本身
- volume的生存周期独立于容器的生存周期,即使删除容器,volume仍然存在,没有任何容器使用的volume也不会被Docker删除
Docker提供来volumedriver接口,并默认实现了local驱动,使用宿主机的文件系统为Docker容器提供volume。
3.7.1 数据卷使用方式
为容器添加volume类似于mount操作,用户将一个文件夹作为volume挂载到容器上,多个容器可以共享同一个volume。
1➜ ~ docker volume
2
3Usage: docker volume COMMAND
4
5Manage volumes
6
7Options:
8 --help Print usage
9
10Commands:
11 create Create a volume
12 inspect Display detailed information on one or more volumes
13 ls List volumes
14 prune Remove all unused volumes
15 rm Remove one or more volumes
16
17Run 'docker volume COMMAND --help' for more information on a command.
(1)创建volume
创建指定名字的volume
1docker volume create --name vol_simple
Docker当前并未对volume的大小提供配额管理,用户创建volume时也无法指定volume的大小,同时采用默认local volumedriver,volume的文件系统使用宿主机的文件系统。
在使用docker run或docker create创建新容器时,也可以使用-v标签为容器添加volume,下面分别为容器创建了一个随机名字的volume与指定名字的volume,挂载到了容器中的/data目录下。
1docker run -d -v /data ubuntu /bin/bash
2docker run -d -v vol_simple:/data ubuntu /bin/bash
Docker创建volume时会在宿主机/var/lib/docker/volume中创建一个以volume ID为名的目录,并将volume中的内容存储在 _data目录下。
(2)挂载volume
用户可以将自行创建或者由Docker创建的volume挂载到容器中,也可以将宿主机上目录或者文件作为volume挂载到容器中,若镜像中原本存在文件夹或文件,它们会被隐藏,以保持与宿主机中的内容一致。
(3)使用Dockerfile添加volume
1VOLUME /data
在使用Docker build命令生成镜像时并且以该镜像启动容器时会挂载一个volume到/data,与上文中vol_simple例子类似,若镜像中存在 /data 文件夹,则文件夹中的内容将全部被复制到宿主机中对应的文件夹中,并且根据容器中的文件夹设置合适的权限和所有者。
类似的,可以使用VOLUME指令添加多个volume
1VOLUME ["/data1","/data2"]
与使用docker run -v不同的是,为保证Dockerfile的可移植性,VOLUME指令并不能挂载主机中指定的文件夹。
3.7.2 数据卷原理解读
Docker的volume本质是容器中的一个特殊目录,在容器的创建过程中,Docker会将宿主机上的指定目录(一个以Volume ID为名的目录,或者指定的宿主机目录)挂载到容器中指定的目录上,这里使用的挂载方法是绑定挂载(bind mount),挂载完成后宿主机目录和容器内的目标目录一致。
在处理完所有的mount操作之后,Docker只需要通过chdir和pivot_root切换进程的根目录到rootfs中,这样容器内部就只能看见以rootfs为根的文件内容以及被mount到rootfs之下的各项目录了。
(1)创建volume
无论用户使用什么方式创建或运行一个戴volume的容器,volume的来源只有两种,即用户通过命令行指定的绑定挂载和从其他容器共享。Docker首先根据用户指定的volume类型,判断并创建新的挂载点。
创建volume过程的主要操作
- 解析并生成参数列表,每个参数描述了一个volume和容器的对应关系或是一个容器与其他容器共享volume的情况
- 初始化,使用参数列表生成挂载点列表,这一过程在创建容器时执行,即在宿主机和容器文件目录下创建上述挂载点中所需的路径
- 将挂载点列表传递给libcontainer,按挂载点列表执行所有mount操作,完成从宿主机到容器内挂载点的映射,这一过程在容器启动时才会执行
综上所述,volume的创建依照容器启动过程可以明显地分为两个阶段,第一阶段为容器创建阶段,Docker根据两种不同的volume来源组装挂载点列表,第二阶段为容器启动阶段,libcontainer使用组装好的挂载点列表进行进行mount操作,完成volume的创建
下面对容器创建过程中,两种不同来源volume的挂载点组装进行详细解释
对用户通过命令行指定的绑定挂载,Docker会从用户输入参数中解析出宿主机上源目录路径(可选)、volume名字(可选)、容器内挂载位置(可选)、挂载模式(可选)等几个变量,并且会对挂载位置是否为绝对路径进行检查
在对用户输入的参数进行解析后,若用户未指定volume名,则会生成一个随机的volume名。Docker维护了一个本地的volume列表,列表中存储了所有本地有名字的volume,列的键为volume名,值为volume的存储路径和驱动名称。若用户指定了volume名,Docker会在volume列表中查找是否已经有对应的volume,若未找到,Docker会创建一个以此名字命名的volume,并将该volume加入到Docker维护的volume列表中,然后创建一个新的挂载点,若找到了对应的volume,则将其中的信息复制到新创建的挂载点中(主要信息为volume的源地址)
Docker为每一个容器都维护着如下所示的挂载点组成的列表

对于共享的volume,Docker从输入参数中解析出“volume容器ID”、“是否可读”两个变量,接着根据容器ID查找到对应的容器对象Container,然后根据该对象中volumes数组复制并创建新的挂载点,并加入到上面提到的挂载点列表中

从两种不同方式得到挂载点后,两种不同的volume来源被同一成格式相同的挂载点,Docker无需关心volume从何而来,只需读取挂载点列表中的各个挂载点中的信息,就可以完成绑定,过程发生在容器启动阶段
首先Docker根据目的目录的级数对挂载点列表中的挂载点进行排序,来确保正确的挂载顺序,确保挂载操作不存在覆盖,如避免/container/dir对/container的覆盖,然后Docker将挂载点改装成libcontainer可以识别的格式,并将其中的Device字段指定为bind,接下来Docker将新的挂载点列表传递给libcontainer,每个列表项的格式如下
1Source: m.Source,
2Destination: m.Destination,
3Device: "bind",
4Flags: flags,
5PropagationFlags: pFlags,
其中挂载的源是宿主机上的路径,目标是容器中的路径,并设置对应的读写权限和拓展选项,这个列表就是最终组装好的一个mount指令所需的参数,对libcontainer而言,只需安装上述参数指定mount命令就可以完成volume的挂载了
(2)删除volume
删除volume的两种方法
- 使用docker volume rm命令删除
- 使用docker run --rm和docker rm -v在删除容器时删除关联的volume
使用第一种方式时,Docker首先检查是否还有容器使用这个volume,若有,则返回错误信息并终止删除,若没有容器在使用这个volume,那么Docker会将这个volume在宿主机上对应的目录删除,并删除其维护的本地volume列表中的相关信息
使用第二种方式时,volume删除过程与第一种类似,但这种方式会过滤掉挂载点中Named字段为true的volume,不会删除命名的volume
(3)volume相关的配置文件
/var/lib/docker/containers文件夹下有以容器ID命名的子文件夹,文件夹中的config.json是容器的配置文件,也包含容器使用的volume ID及它们的可写情况,/var/lib/docker/volumes文件夹下有以volume ID或volume名字命名的子文件夹,文件夹中的 _data目录存储了该volume中的所有内容
3.8 Docker网络管理
3.8.1 Docker网络基础
(1)Docker网络架构
Docker在1.9版本中引入了一整套的docker network子命令和跨主机网络的支持,允许用户根据应用拓扑结构创建虚拟网络并将容器接入其对应的网络,早在Docker 1.7中,网络部分代码已单独抽离为libnetwork,此后,容器的网络模式也被抽象变成了统一接口的驱动。
Docker公司在libnetwork中使用了CNM(Container Network Model)来标准化网络驱动开发步骤和支持多种网络驱动,CNM定义了构建容器虚拟化网络的模型,同时还提供了可以用于开发多种网络驱动的标准化接口和组件。
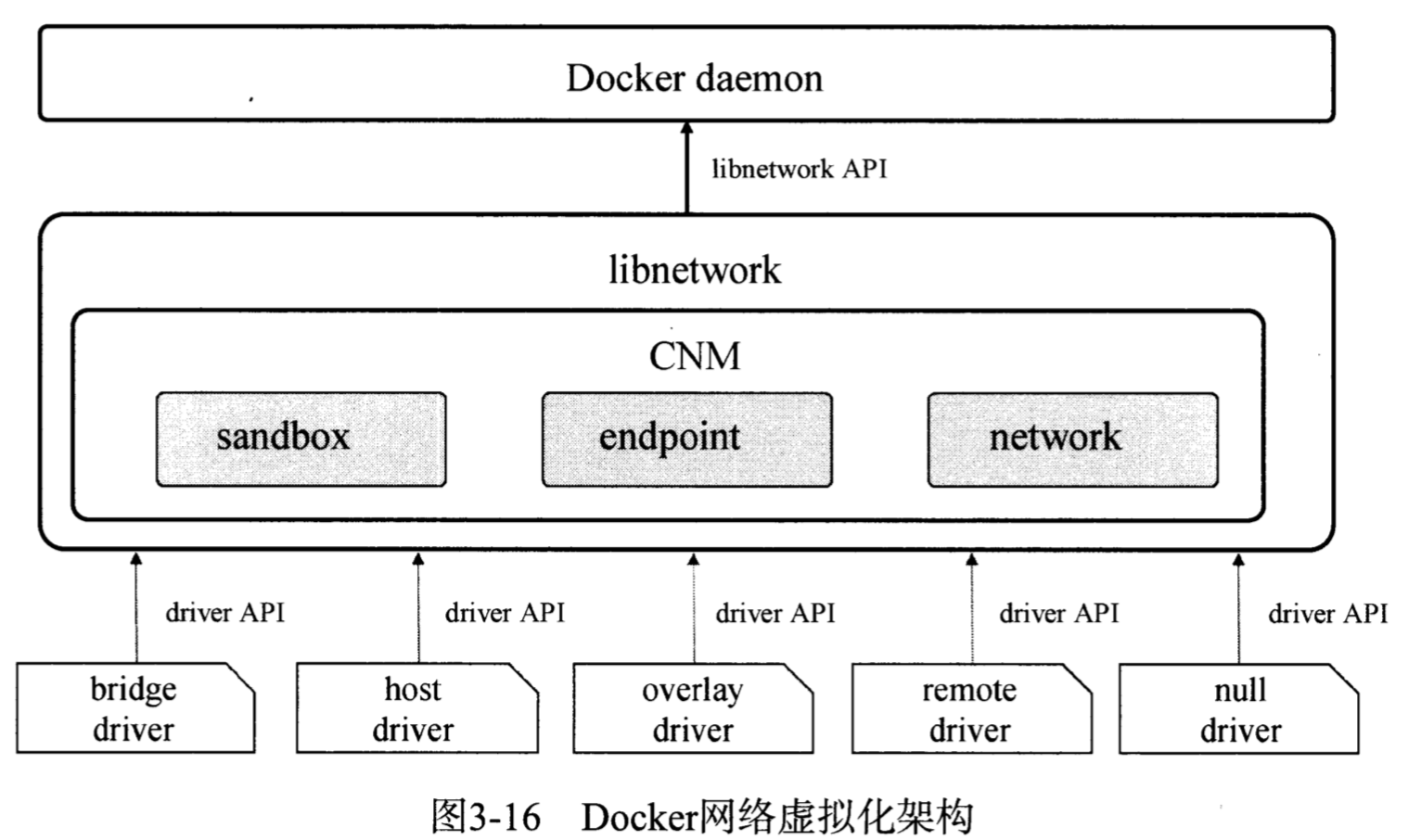
Docker Daemon通过调用libnetwork对外提供的API完成网络创建和管理功能,libnetwork中则使用CNM来完成网络功能的提供。CNM中主要有沙盒(sandbox)、端点(endpoint)和网络(network)这3种组件,libnetwork中内置的5种驱动则为libnetwork提供了不同类型的网络服务。
CNM中的三个核心组件如下
- 沙盒:一个沙盒包含了一个容器网络栈的信息。沙盒可以对容器的接口、路由和DNS设置等进行管理,沙盒的实现可以是Linux network namespace、FreeBSD Jail或者类似的机制,一个沙盒可以有多个端点和多个网络
- 端点:一个端点可以加入一个沙盒和一个网络。端点的实现可以是veth pair、Open vSwitch内部端口或相似的设备,一个端点只可以属于一个网络并且只属于一个沙盒
- 网络:一个网络是一组可以直接互相联通的端点。网络的实现可以是Linux Bridge、VLAN等,一个网络可以包含多个端点
libnetwork中的5种内置驱动如下
- bridge驱动:Docker默认设置,使用该驱动时,libnetwork将创建出来的Docker容器连接到Docker网桥上,与外界通信使用NAT,增加了通信的复杂度,在复杂场景下使用会有诸多限制
- host驱动:使用该驱动时,libnetwork将不为Docker容器创建网络协议栈,即不创建独立的netwok namespace,Docker容器中的进程处于宿主机网络环境下,相当于Docker容器与宿主机共用同一个network namespace,使用宿主机的网卡、IP和端口等信息,但文件系统、进程表等还是与宿主机隔离。host模式很好解决了容器和外界通信的地址转换问题,可以直接使用宿主机的IP进行通信,不存在虚拟化网络带来的额外负担,但降低了网络层面的隔离性,引起网络资源的竞争和冲突,host驱动适用于容器集群规模不大的场景
- overlay驱动:该驱动采用IETF标准的VXLAN方式,并且是其中被普遍认为最适合大规模云计算虚拟化环境的SDN controller模式。使用过程需要一个额外的配置存储服务,如Consul、etcd、ZooKeeper,启动Docker Daemon时需要添加参数指定使用的配置存储服务地址
- remote驱动:该驱动实际上并未做真正的网络服务实现,而是调用了用户自行实现的网络驱动插件,实现了libnetwork的驱动可插件化
- null驱动:使用该驱动时,Docker容器拥有自己的network namespace,但是并不为Docker容器进行任何网络配置,Docker容器除了network namespace自带的loopback网卡外,没有其他任何网卡、IP、路由等信息,需要用户自行配置
docker network命令一览,与docker volume类似
1➜ ~ docker network
2
3Usage: docker network COMMAND
4
5Manage networks
6
7Options:
8 --help Print usage
9
10Commands:
11 connect Connect a container to a network
12 create Create a network
13 disconnect Disconnect a container from a network
14 inspect Display detailed information on one or more networks
15 ls List networks
16 prune Remove all unused networks
17 rm Remove one or more networks
18
19Run 'docker network COMMAND --help' for more information on a command.
下面使用命令构建一个如图所示的网络应用
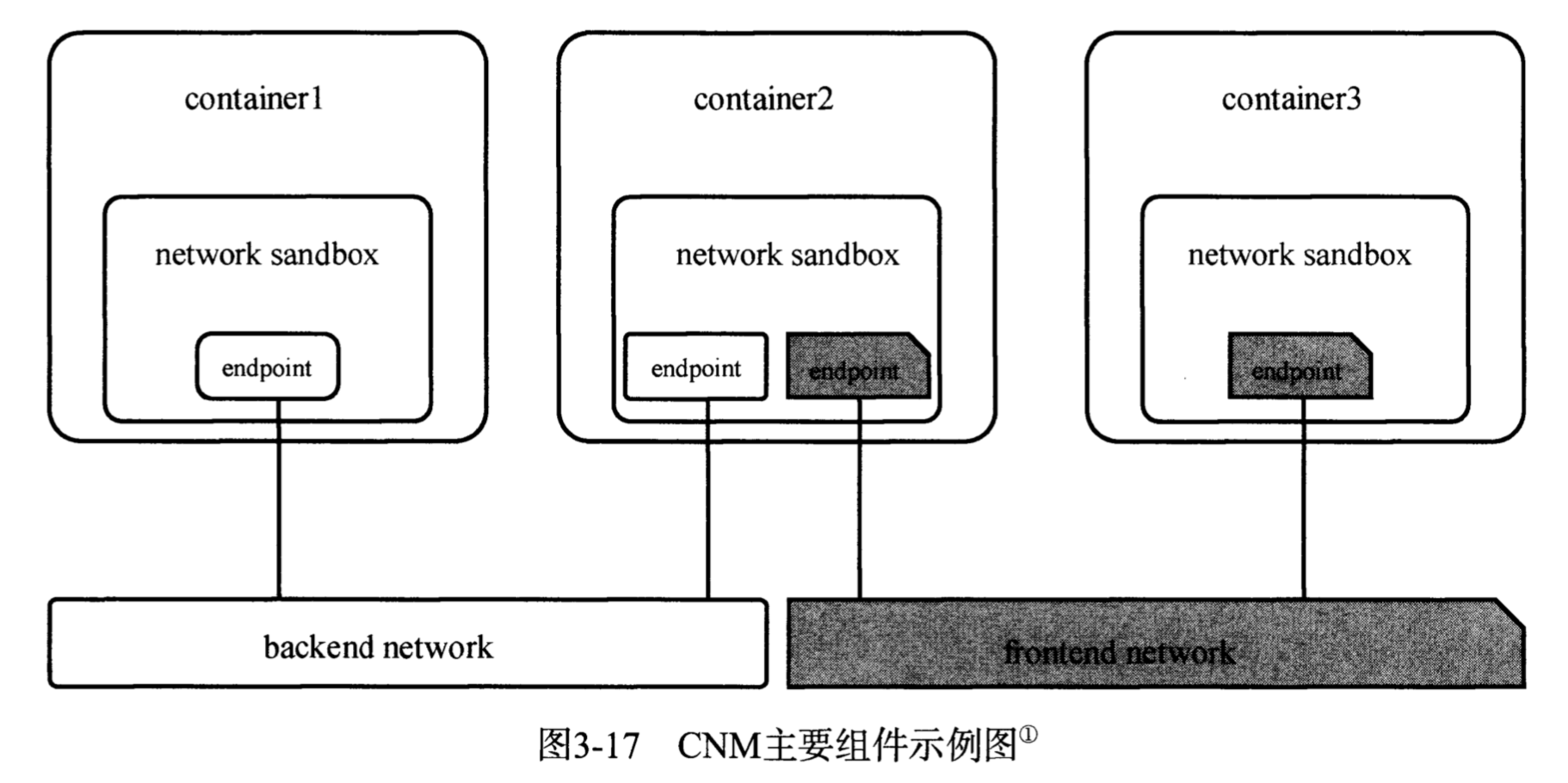
1//创建前段与后端网络,两个网络互不连通
2docker network create backend
3docker network create frontend
4//创建三个容器并加入网络中
5docker run -it --name container1 --net backend busybox
6docker run -it --name container2 --net backend busybox
7docker run -it --name container3 --net frontend busybox
8//将container2加入到frontend网络中,container2拥有两块网卡,同时与container1和container3连通
9docker network connect frontend container2
(2)bridge驱动实现机制分析
1)docker0网桥
在宿主机上安装好Docker后,会增加一个名为docker0的网卡,宿主机同时在内核路由表上添加一条到达相应网络的静态路由。然后使用docker run命令运行一个执行shell的容器,假设容器名为con1,在容器中可以看到两块网卡,lo为容器的回环网卡,eth0为容器与外界通信的网卡,IP地址与宿主机上的docker0在同一网段,con1的默认网关也是宿主机的docker0网卡。这时在其他终端查看宿主机的网络设备,可以看到一块veth开头的网卡,veth pair总是成对出现,用来连接两个network namespace,另一个则是con1中的eth0。
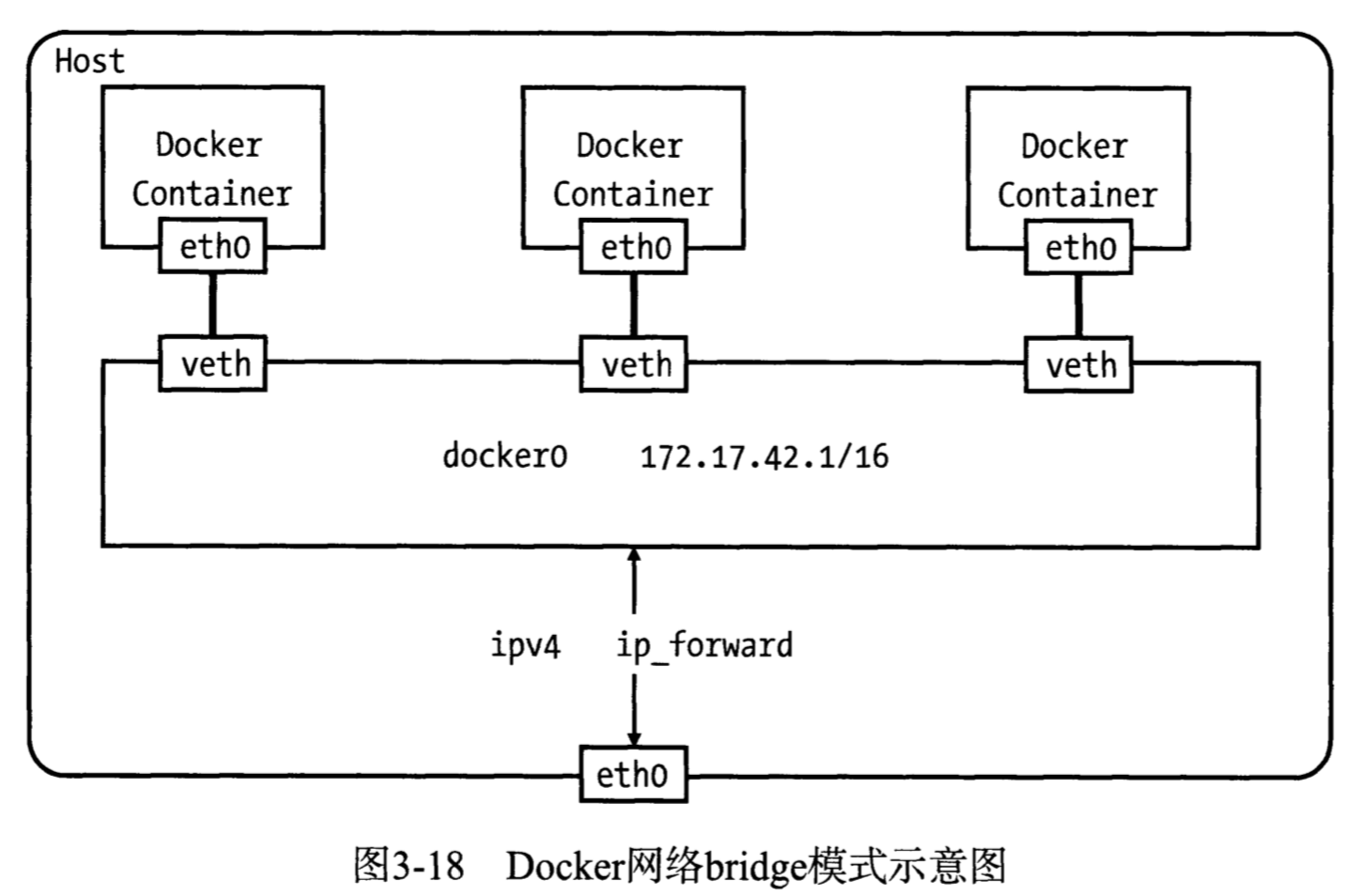
如图所示,Bridge模式下创建了docker0网桥,并以veth pair连接各容器的网络,容器中的数据通过docker0网桥转发到eth0网卡上。这里网桥的概念等同于交换机,网桥上的veth网卡相当于交换机上的端口,可以将多个容器或虚拟机连接在其上,端口工作在二层,不需要配置IP信息。docker0网桥为连接在其上的容器转发数据帧,使同一台宿主机上的Docker容器之间可以相互通信。docker0是普通的Linux网桥,可配置IP,在Docker桥接网络模式下,其IP地址作为连接于之上的容器默认网关地址存在。在Linux中,可以使用brctl命令查看和管理网桥。
docker0网桥是在Docker Deamon启动时自动创建的,默认IP为172.17.0.1/16,之后创建的Docker容器都会在docker0子网的范围内选取一个未占用的IP使用,并连接到docker0网桥上,Docker提供了如下参数来自定义docker0设置
- --bip=CIDR:设置docker0的IP地址和子网范围,使用CIDR格式,如192.168.100.1/24。这个参数仅仅是配置docke0的,对其他自定义的网桥无效。
- --fixed-cidr=CIDR:限制Docker容器获取IP的范围。Docker容器默认获取的IP范围为Docker网桥的整个子网范围,此参数可将其缩小到某个子网范围内。
- --mtu=BYTES:指定docker0的最大传输单元(MTU)。
除使用docker0网桥外,还可以使用自己创建的网桥,使用--bridge=BRIDGE参数指定,此参数如和--bip参数同时使用时会产生冲突
2)iptables规则
Docker安装完成后,将默认在宿主机系统上增加一些iptables规则,以用于Docker容器和容器之间以及和外界的通信。可以使用iptables-save命令查看。
1-A POSTROUTINIG -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
这条规则保证Docker容器和外界的通信,含义是将源地址为172.17.0.0/16的数据包(即Docker容器发出的数据),当不是从docker0网卡发出时做SNAT(源地址转换,将IP包的源地址替换为相应网卡的地址)。这样从Docker容器访问外网的流量,在外部看来就是从宿主机上发出的,外部感觉不到Docker容器的存在,而外接访问Docker容器则是通过iptables做DNAT(目的地址转换)实现的,以启动一个web服务器为例,将容器5000端口映射到宿主机的5000端口上,iptables相关规则如下
1...
2*nat
3-A DOCKER ! -i docker0 -p tcp -m tcp --dport 5000 -j DNAT --to-destination 172.17.0.4:5000
4...
5*filter
6-A DOCKER -d 172.17.0.4/32 ! -i docker0 -o docker0 -p tcp -m tcp --dport 5000 -j ACCEPT
可以看到在nat和filter的DOCKER链中分别增加了一条规则,将访问宿主机5000端口的流量转发到172.1.0.4的5000端口上,此外Docker的forward规则默认允许所有的外部IP访问容器,可以通过在filter的DOCKER链上添加规则来对外部的IP访问作出限制,例如只允许源IP为8.8.8.8的数据包访问容器
1iptables -I DOCKER -i docker0 ! -s 8.8.8.8 -j DROP
Docker容器之间相互通信也受到iptables规则限制,同一台宿主机上的容器默认都连在docker0网桥上,属于同一子网,同时Docker Daemon会在filter的FORWARD链上增加一条ACCEPT规则(--icc=true)
1-A FORWARD -i docker0 -o docker0 -j ACCPET
当Docker Daemon启动参数--icc设置为false时(icc参数表示是否允许容器间相互通信),以上规则会被设置为DROP,Docker容器间的相互通信就被禁止,此时想让两个容器间通信需要在docker run时使用--link选项
Docker容器和外界通信的过程中,还涉及了数据包在多个网卡间的转发,需要内核将ip-forward功能打开,将ip_forward系统参数设置为1
以上过程中涉及的Docker Daemon启动参数如下
- --iptables:是否允许Docker Daemon设置宿主机的iptales规则,默认为true
- --icc:是否允许Docker容器间相互通信,默认为true(要求--iptables=true)
- --ip-forward:是否将ip_forward参数设为1,默认为true
3)Docker容器的DNS和主机名
主机名并未写入镜像,而是在容器启动后使用虚拟文件覆盖/etc/hostname、/etc/hosts、/etc/resolv.conf,这样能解决主机名的问题,同时也能让DNS及时更新(改变resolv.conf)。
可通过Docker提供的参数修改这些文件
- -h HOSTNAME或者--hostname=HOSTNAME:设置容器的主机名,此名称会写入到/etc/hostname和/etc/hosts文件中,为docker run命令参数
- --dns=IP_ADDRESS...:为容器配置DNS,写在/etc/resolv.conf中,此参数可以在Docker Daemon启动时设置,也可以在docker run时设置,默认为谷歌DNS
对以上3个文件的修改不会被docker commit保存,重启容器也会导致修改失效
3.8.2 Docker Daemon网络配置原理
网络部分分为Daemon启动时,在主机系统上所做的网络设置,可以被所有容器使用,以及针对具体容器,启动容器时所做的网络配置。这一部分代码在Docker 1.6前,分别包含在Docker Daemon及libcontainer中,而Docker 1.7以后,独立为libnetwork,通过插件的形式,允许用户根据需求实现自己的network driver。
Docker Daemon网络初始化部分(以bridge驱动为例)
(1)与网络相关的配置参数
Docker Daemon启动过程中,配置参数Config中保存了用于网络配置的bridgeConfig,网络相关的参数都定义在其中,主要包括以下几项:
- EnableIptables:默认为true,对应启动时的--iptables参数
- EnableIpMasq:默认为true,对应启动时的--ip-masq参数,作用为是否为Docker容器通往外界的包做SNAT
- DefaultIp:对应--ip参数,默认为"0.0.0.0",当启动容器做端口映射时,将DefaultIp作为默认使用的IP地址
- EnableForward、Iface、IP、FixedCIDR、InterContainerCommunication分别对应--ip-forward、--bridge、--bip、--fixed-cidr、--icc
(2)初始化过程
- 网络参数校验
- 是否初始化bridge驱动
- 处理网桥参数
- 创建网桥设置队列
- 更新相关配置信息
3.8.3 libcontainer网络配置原理
(1)命令行参数阶段
解析docker run命令参数,存入相应变量config、hostConfig、networkingConfig、cmd等
- Config:保存Hostname、NetworkDisabled、MacAddress等
- HostConfig:保存DNS、NetworkMode
- NetworkingConfig:保存一组端点参数与所属网络名的map
(2)创建容器阶段
- 校验config、hostConfig、networkingConfig中的参数
- 根据需要调整hostConfig参数
- 根据传入容器配置和名称创建对应的容器
容器创建最终返回的Container对象中的NetworkSettings属性描述了容器的具体网络信息,主要包括
- Bridge:容器所连接到的网桥
- SandboxID:容器对应的Sandbox的ID
- HairpinMode:是否开启hairpin模式
- Ports:容器映射的端口号
- SandboxKey:Sandbox对应的network namespace文件路径
- Networks:保存了容器端点配置与所属网络名的map
- IsAnonymousEndpoint:容器是否未指定名字name
(3)启动容器阶段
- initializeNetwork:初始化Container对象中与网络相关的属性
- populateCommand:填充Docker Container内部需要执行的命令,Command中含有进程启动命令,还含有容器环境的配置信息,也包括网络配置
- container.waitForStart:实现Docker Container内部进程的启动,进程启动之后,为进程创建网络环境
(4)execdriver网络执行流程
network namespace的配置通过调用execdriver的createNetwork函数实现,根据Docker容器的不同网络模式,流程如下:
- 根据execdriver.Command对象中的Network属性判断出采用不同的方式配置网络
- 若Network.ContainerID不为空,则为container模式,首先在处于活动状态的容器列表中查找被引用的容器,并获取容器中进程的network namespace路径,将该路径加入到libcontainer.Config.Namespaces中
- 若Network.NamespacePath不为空,对应host模式,将Network.NamespacePath写入libcontainer.Config.Namespaces中
- 其他情况下,表示目前暂时无法获取network namespace,则为libcontainer设置PreStart钩子函数,主要工作是遍历execdriver提供的preStart钩子函数并执行
(5)libcontainer网络执行流程
在libnetwork被分离出之前,Docker网络的内核态网络配置是由libcontainer完成的,Docker 1.7及之后,并不会在libcontainer中创建网络环境
(6)libnetwork实现内核态网络配置
libnetwork对内核态网络配置主要包括启动容器和libcontainer网络执行流程两个阶段
1)启动容器
函数network.CreateEndpoint通过处理传入的endpoint参数和默认配置构建endpoint对象,再调用addEndpoint函数,获取network对应的驱动driver,调用驱动层的CreateEndpoint在网络驱动层创建endpoint。以bridge驱动为例,实际工作为veth网络栈的创建,主要流程如下
- 处理endpoint对象参数并创建bridgeEndpoint对象
- 分别生成host端和container端(也就是sandbox)veth设备的名字并组建Veth对象,调用netlink.LinkAdd函数创建veth pair设备,再分别为两个veth设备配置MTU
- 调用addToBridge将host端veth设备加入网桥
- 将container端veth设备的名字和传入的interface参数(MAC地址、IP地址等)配置给bridgeEndpoint,停用该veth设备并配置MAC地址
- 启用host端veth设备
- 调用allocatePorts函数处理端口映射
2)libcontainer网络执行流程
libcontainer触发的配置网络的钩子函数最后调用了libnetwork的sandbox.SetKey函数,主要流程如下
- 若原来sandbox的network namespace已存在的话,则释放资源
- 根据sandbox的Key创建文件并与传入的network namespace路径进行绑定
- 若原来的network namespace存在并且为它分配了resolver,则为当前sandbox重新启动
- 遍历sandbox的所有endpoint,对每一个调用populateNetworkResources函数配置网络资源
setKey最终调用了osl/interface_linux.go中的AddInterface进行interface配置,osl包主要是对操作系统层的封装,下面的函数流程仍然是针对上面使用bridge驱动创建的endpoint
除interface参数的处理配置,AddInterface的主要工作是构建两个函数prefunc和postfunc,并以此为参数调用nsInvoke,执行流程如下
- nsInvoke函数打开传入的network namespace路径,获取文件描述符nsFd,并以此调用prefunc
- prefunc函数通过传入的名字获取对应的interface(container端veth设备),再调用LinkSetNsfd将veth设备加入nsFd对应的namespace中
- 回到nsInvoke函数调用netns.Set将当前进程的network namespace设置为nsFd对应的namespace
- 调用postfunc函数,根据名字获取veth设备的interface,停用该设备,并将前面interface的参数配置到veth设备的interface上,再启用设备,最后为veth设备配置路由规则
- defer语句生效,调用ns.SetNamespace恢复该进程的network namespace
至此,bridge的veth网络栈配置完成,以上函数的底层操作都是由netlink包通过系统调用来实现
3.8.4 传统的link原理解析
要使用容器间通信时,若使用端口映射的方式,需要经过NAT,不够安全且效率也不高,这时就需要使用Docker的连接(linking)系统,它可以在两个容器之间建立一个安全的通道,使得接收容器(如web应用)可以通过通道得到源容器(如数据库服务)指定的相关信息。
Docker 1.9版本后,网络操作独立为一个命令组(docker network),link系统也与原来不同了,Docker为了保持对向上兼容,若容器使用默认的bridge模式网络,则会默认使用传统的link系统,而使用用户定义的网络(user-defined network),则会使用新的link系统。
(1)使用link通信
link是在容器创建的过程中通过--link参数创建的,参数格式为--link <name or id>:alias,其中name是容器通过--name参数指定或自动生成的名字,而不是容器的主机名,alias为容器的别名。
1docker run -d --name db postgres/10
2docker run -d -P --name web --link db:webdb webapp/10
web容器可以从db容器中获取数据,web容器叫做接收容器或者父容器,db容器叫做源容器或子容器,一个接收容器可以设置多个源容器,一个源容器也可以有多个接收容器,Docker将连接信息以下面两种方式保存在接收容器中
- 设置接收容器的环境变量
- 更新接收容器的/etc/hosts文件
(2)设置接收容器的环境变量
当两个容器通过--link建立连接后,会在接收容器中设置一些环境变量,以保存源容器的一些信息,包括
- 每增加一个源容器,接收容器就设置一个名为<alias>_NAME环境变量,alias为源容器的别名
- 预先在源容器中设置的部分环境变量也会设置在接收容器的环境变量中,包括Dockerfile中使用ENV命令设置的,以及docker run命令中-e、--env=[]参数设置的,例如db中包含doc=docker,则web中包含WEBDB_ENV_doc=docker
- 接收容器同样会为源容器中暴露的端口设置环境变量,例如db容器IP为172.17.0.2,且暴露8080的tcp端口,web容器中会看到如下环境变量
- WEBDB_PORT_8080_TCP_ADDR=172.17.0.2
- WEBDB_PORT_8080_TCP_PORT=8080
- WEBDB_PORT_8080_TCP_PROTO=8080
- WEBDB_PORT_8080_TCP=tcp://172.17.0.2:8080
- WEBDB_PORT=tcp://172.17.0.2:8080
--link是docker run的命令参数,也就是说link是在启动容器的过程中创建的,执行过程(setupLinkedContainers函数)如下
- 找到要启动容器的所有子容器,即所有连接到的源容器
- 遍历所有源容器,将link信息记录起来
- 将link相关的环境变量放入到env中,最后将env变量返回
- 若上述过程中出现错误,则取消做过的修改
注意,传统的link方式中,要求当前容器和所有的源容器都必须在默认网络中
(3)更新接收容器的/etc/hosts文件
Docker容器的IP地址是不固定的,容器重启后IP地址可能与之前不同,在有link关系的两个容器中,接收容器包含有源容器的IP和环境变量,但源容器重启时,接收方容器中的环境变量并不会自动更新,因此link操作除将link信息保存在接收方容器中外,还在/etc/hosts中添加了一项源容器的IP和别名,用以来解析源容器的IP地址,并且当源容器重启后,会自动更新接收容器的/etc/hosts文件。
Docker容器/etc/hosts文件的设置是在容器启动时完成的,当一个容器重启后,自身的hosts文件和以自己为源容器的接收容器的hosts文件都会更新,保证link系统的正常工作。
(4)建立iptables规则进行通信
在接收容器上设置了环境变量和更改了hosts文件后,接收容器只是得到了源容器的相关信息,Docker Daemon还会为连接的容器添加特定iptables规则来保证容器间的通信。
以web和db的例子解释,假设db暴露了tcp/5432端口,web容器IP为172.17.0.2/16,db容器IP为172.17.0.1/16,则web容器和db容器建立连接后,主机上可以看到如下iptables规则
1-A DOCKER -s 172.17.0.2/32 -d 172.17.0.1/32 -i docker0 -o docker0 -p tcp -m tcp --dport 5432 -j ACCPET
2-A DOCKER -s 172.17.0.1/32 -d 172.17.0.2/32 -i docker0 -o docker0 -p tcp -m tcp --sport 5432 -j ACCPET
处理端口映射的过程是在启动容器阶段创建endpoint的过程中,以bridge驱动为例,CreateEndpoint最后会调用allocatePort来处理端口暴露,这里需要注意两点
- 得到源容器所有暴露出来的端口。这里是容器全部暴露的端口,而不仅仅是和主机做了映射的端口
- 遍历容器暴露的端口,为每一个端口添加如上的两条iptables规则
link是一种比端口映射更亲密的容器间通信方式,提供来更安全、高效的服务,通过环境变量和/etc/hosts文件的设置提供了从别名到具体通信地址的发现,适合于一些需要各组件间通信的应用。
3.8.5 新的link介绍
相比于传统的link系统名字和别名解析、容器间网络隔离(--icc=false)以及环境变量注入,Docker v1.9后为用户自定义网络提供了DNS自动名字解析、同一个网络中容器间的隔离、可以动态加入或者退出多个网络、支持--link为源容器设定别名等服务。在使用上,初了环境变量注入,新的网络模型给用户提供了更便捷和更自然的使用方式而不影响原有的使用习惯。
在新的网络模型中,link系统只是在当前网络给源容器起了一个别名,并且这个别名只对接收容器有效。新旧link系统的另一个重要区别是新的link系统在创建一个link时,并不要求源容器已经创建或启动。通过DNS解析的方式提供名字和别名的解析,解决了传统link系统中由于容器重启造成注入的环境变量更新不及时的问题。
3.9 Docker与容器安全
3.9.1 Docker的安全机制
Docker目前已经在安全方面做了一定的工作,包括
- Docker Daemon以TCP形式提供服务的同时使用TLS,默认Unix域套接字的通信方式需要进入Daemon宿主机所在机器并且有权访问才可以建立通信
- 在构建和使用镜像时会验证镜像的签名证书,Docker v1.3引入镜像数字签名功能,但镜像校验功能只在使用V2 registry时才生效,需用户进行docker login登录
- 通过cgroups及namespaces来对容器进行资源限制和隔离
- 提供自定义容器能力(capability)的接口,能力表示表示了一组所能执行的系统调用操作,若是root用户,被剥夺能力时也无法进行相应的系统调用,而对普通用户,可以在不赋予超级用户权限的情况下增加一些能力,对应docker run命令中--cap-add、--cap-drop指令,下面是一些较为主要的能力
- CHOWN:允许任意更改文件UID和GID
- DAC_OVERRIDE:允许忽略文件的读、写、执行访问权限检查
- FSETID:允许文件修改后保留setuid/setgid标志位
- SETGID:允许改变进程组ID
- SETUID:允许改变进程用户ID
- SETFCAP:允许向其他进程转移或或者删除能力
- NET_RAW:允许创建RAW和PACKET套接字
- MKNOD:允许使用mknod创建指定文件
- SYS_REBOOT:允许使用reboot或者kexec_load,kexec_load能力是加载新的内核作为reboot重启启动所需内核
- SYS_CHROOT:允许使用chroot
- KILL:允许发送信号
- NET_BIND_SERVICE:允许绑定常用端口号(端口号小于1024)
- AUDIT_WRITE:允许审计日志写入
- 通过定义seccomp profile限制容器内进程系统调用的范围等。seccomp(secure computing mode)是Linux的一种内核特性,可用于限制进程能够调用的系统调用范围,从而减少内核的攻击面,被广泛应用于构建沙盒。
3.9.2 Docker安全问题
(1)磁盘资源限制问题
容器本质上是一个进程,通过镜像层叠的方式来构建容器的文体系统,但改写文件的本质还是在宿主机文件系统的某一目录下存储这些信息,所有容器的rootfs最终存储在宿主机上。
(2)容器逃逸问题
在全虚拟化和半虚拟化中,每个租户都独立运行一个内核,比Docker使用操作系统虚拟化更安全,操作系统虚拟化指的是共享内核、内存、CPU及磁盘等,所以容器的安全问题特别突出,其中以容器逃逸问题最为突出。著名的shocker.c程序通过open_by_handle_at调用暴力扫描宿主机文件系统获取宿主机敏感文件,以此达到逃逸效果。
(3) 容器DoS攻击与流量限制问题
目前在公网上的DoS攻击预防已经有了很成熟的产品,对传统网络有比较好的防御效果,但随虚拟化技术兴起,攻击数据包可能不需要通过物理网卡就可以攻击同一个宿主机下的其他容器。默认的Docker网络是网桥模式,所有容器连接到网桥上,实际上所有容器在共用一张物理网卡,如果同一宿主机上的某一个容器抢占了大部分带宽,将会影响其他容器的使用。
(4)超级权限问题
Docker在0.6版本时给容器引入了超级权限,可以在docker run时加上--privileged参数,使容器获得超级权限,在启动容器时,一是获取所有能力赋值给容器,二是扫描宿主机所有设备文件挂载到容器内。
1)GetAllCapabilities 能力的主体是进程,通过限制各个进程的能力来限制用户的权限,能力分为
- effective:进程当前有效能力位图
- permitted:进程可以使用的能力位图,与effective的区别在于permitted可以有很多能力,但进程不一定用,可以通过系统调用进行更改,最多不超过permitted赋予但能力
- inheritable:进程的子进程可以继承的能力位图
- bounding:inheritable能力的超集,用来限制可以加入到inheritable集合的能力
GetAllCapabilities相当于把超级用户但权限全部赋值给当前容器,可以通过cat /proc/$PID/status查看进程的能力位图
2)GetHostDeviceNodes
获取宿主机目录下的所有设备文件,并将其设置到容器,即同步容器与宿主机的/dev目录(一些CUDA镜像就需要获取显卡设备才能运作)
3.9.3 Docker安全的解决方案
- 限制进程访问的资源:SELinux技术
- 限制容器磁盘使用量:quota等技术
- 流量控制:traffic controller技术
(1)SELinux
1)SELinux概述
SELinux是由内核实现的MAC(Mandatory Access Control,强制访问控制),可以说SELinux就是一个MAC系统。SELinux为每一个进程设置一个标签,称为进程的域,为文件设置标签,称为类型。每一个标签由User、Role、Type和Level等4部分组成。
- User:SELinux用户是由权限构成的集合,而非Linux用户。系统在登录时为Linux用户匹配一个SELinux用户,通过semanage login -l可以看到Linux用户和SELinux用户的映射
- Type:Type是SELinux访问控制的基础,描述进程所能访问的资源类型。常见文件资源的类型有blk_file(块文件)、chr_file(字符文件)、dir(目录)、fd(文件描述符)、fifo_file(fifo文件)、filesystem(文件系统)、lnk_file(链接文件)和sock_file(套接字文件)等。容器文件一般表示为svirt_sandbox_file_t或svirt_lxc_file_t。容器域有很多,不同类型的容器需求不一样,容器域一般使用svirt_lxc_virt_t来标示其域,也可以自己为容器定义域。
- Role:角色是一些类型的组合,是用户和类型的过渡。一个用户可以有多个角色,一个角色可以使用不同的类型。
- Level:定义更加具体的权限,可以有两种选择,MLS(多层级安全)或MCS(多级分类安全)。
MLS从高到低将权限分为TopSecret、Secret、Condifidental和Unclassified等4个等级,采用BLP模型,对每一个实体进行分类,高级别的实体不可以写低级别的实体,低级别的实体不可以读高级别的实体,所有信息从低级别流向高级别,保证了信息的安全。
MCS是另一种方式,通过一个敏感度和一个分类来表示。敏感度有严格的分级,从s0到s15,一共分16级,标号越高,敏感度等级越高。分类用来进行数据划分,对文件的同一类型或同一域的数据打上标签。当你需要访问数据时,必须有足够的敏感度和正确的分类。同一类别下,高等级敏感度可以读低等级敏感度的数据,低等级可以向高等级数据汇报写入。
1查看进程上下文:ps -efZ
2查看文件上下文:ls -Z
3查看当前用户上下文:id -Z
2)SELinux的3种模式
setenforce命令可以用来设置SELinux工作模式,getenforce可以用来获取当前SELinux的状态,1、0、-1分别代表如下模式
- Enforcing:SELinux策略被强制执行,根据策略来拒绝或者通过操作
- Permissive:SELinux策略并不会执行,原本在Enforcing模式下应该被拒绝的操作,在该模式下只会触发安全事件日志记录,而不会拒绝此操作的执行
- Disabled:SELinux被关闭,SELinux不会执行任何策略
3)SELinux的3种访问控制方式
- Type Enforcement:类型强制,SELinux下的主要访问控制机制
- Role-Based Access Control(RBAC):基于SELinux用户,而不是普通用户
- Multi-Level-Security(MLS):多级分类安全,也就是我们所指定的标签
4)类型强制访问控制
在SELinux中,所有访问都必须是明确授权的,即默认情况下未授权的访问都会被拒绝。SELinux是对仙游的以用户或用户组来进行文件读、写和执行的安全增强,并非替换掉原有的安全认证体系。SELinux采用策略来关联主体和客体的级别,在策略中明确指定规则。一条SELinux规则由以下4部分组成。
- 源类型:进程的类型,称为域
- 目标类型:被进程访问的客体的类型,称为类型
- 客体类别:指定允许访问的客体类别
- 权限:指定源类型可以对目标类型所作的操作
例如
1allow sshd_t console_device_t : chr_file { ioctl write getattr lock append open }
源类型为sshd_t,允许访问console_device_t类型客体,源类型可以在客体执行的权限是ioctl write getattr lock append open等操作
5)为什么在Docker中使用SELinux
- SELinux把所有进程和文件都打上标签,进程之间相互隔离SELinux策略控制进程如何访问资源,也就是限制容器如何如访问资源。
- SELinux策略是全局的,它不是针对具体用户设定,而是强制整个系统去遵循,使攻击者难以突破。
- 减少提权攻击的风险,如果一个进程被攻陷,攻击者将会获得该进程的所有权限,访问该进程能访问的权限。
SELinux不是一个杀毒软件,不能替换防火墙、密码等其他安全体系,SELinux不是对现有安全体制进行替换,而是添加一道严格的防线而已。
6)Docker中启用SELinux
Docker启动时执行docker -d --selinux-enabled=true让Docke Daemon启用SELinux,前提是宿主机的SELinux已处于enforcing或者Permissive状态。对不同的应用需要设置不同的能力,对应用的能力进行定制化。
docker run时可以指定容器的user、role、type、level等标签信息
1--security-opt="label:user:USER"
2--security-opt="label:role:ROLE"
3--security-opt="label:type:TYPE"
4--security-opt="label:level:LEVEL"
5--security-opt="label:disable"
6--security-opt="label:apparmor:PROFILE"
容器进程默认标签为system_u:system_r:svirt_lxc_net_t(分别对应用户、角色、类型),容器文件的默认文件类型为system_u:object_r:svirt_sanbox_file_t。默认的层级将由Docker生成,由一个敏感度以及两个MCS级别组成,Docker保证生成的层级的唯一性。当用户通过上述指令指定用户、角色、类型和层级时,将覆盖默认类型。
通过添加--security-opt参数设置容器进程的用户、角色、域、级别等信息,若启用了SELinux而docker run时不指定标签信息,那么将会运行失败,查看Daemon日志,会看到Permission Denied信息。Docker对前文中提到的SELinux的3种访问控制方式均有支持。
- TE形式:docker run -it --security-opt="label:type:svirt_lxc_net_t" ubuntu:trusty /bin/bash
- MCS形式:docker run -it --security-opt label:level:s0:c100,c200 ubuntu:trusty /bin/bash
- MLS形式:docker run -it --security-opt label:level:TopSecret ubuntu:trusty /bin/bash
同一类型进程,每一个进程有自己独有的目标文件。例如Docker创建每一个容器的进程域相同,但是进程的MCS是不一样的,能够访问的目标文件也不一样,这样做到了容器之间的相互隔离,Docker Daemon会为每一个容器分配两个MCS级别,这样容器与容器的文件也得隔离。
(2)磁盘限额
Docker目前提供--storage-opt=[]来进行磁盘限制,但只支持Device Mapper文件系统的磁盘限额,其他几种存储引擎都还不支持,由于cgroups没有对磁盘资源进行限制,Linux磁盘限额使用的quota技术主要是基于用户和文件系统的,基于进程或者目录磁盘限额还是比较麻烦,下面提供几种可能解决方案去实现容器磁盘限额
- 为每一个容器创建一个用户,所有用户共用宿主机上的一块磁盘,通过限制用户在磁盘上的使用量来限定容器的磁盘使用量。只对普通用户有用,对超级用户没有限制。
- 选择支持可以对某一个目录进行限额的文件系统支持,例如XFS可以支持用户、用户组、目录、项目等形式对磁盘使用量进行限制。
- 让Docker定期检查每个容器的磁盘使用量。
- 创建虚拟文件系统,并仅供某一个容器使用。
(3)宿主机内容器流量限制
1)traffic controller概述
traffic controller是Linux的流量控制模块,原理是为数据包建立队列,并且定义了队列中数据包的发送规则,从而实现在技术上对流量进行限制、调度等控制操作。
traffic controller中的流量控制队列分为两种:
- 无类队列:对进入网卡的数据进行统一对待,无类队列能够接受数据包并对网卡流量整形,但不能对数据包进行细致划分,无类队列规定主要有PFIFO_FAST、TBF和SFQ等,流量整形手段主要是排序、限速及丢包
- 分类队列:对进入网卡的数据包根据不同的需求以分类的方式区分对待。数据包进入分类队列后,通过过滤器对数据包进行分类,过滤器返回一个决定,这个决定指向一个分类,队列就根据这个返回的决定把数据包发送到相应的某一类队列中排队。每个子队列内可以再次进行分类,知道不需要分类为止,数据包最终进入相关类的队列中排队。
traffic controller流量控制方式分为4种:
- SHAPING:流量被限制时,它的传输速率就被控制在某个值以下,限制阈值可以远小于有效带宽,这样可以平滑网络的突发流量,使网络更稳定,适用于限制外出的流量
- SCHEDULING:通过调度数据包传输的优先级数据,可以在带宽范围内对不同的传输流按照优先级进行限制
- POLICING:用于处理接收到数据,对数据流量流行进行限制,适用于限制内入的流量
- DROPPING:若流量超过设置的阈值就丢弃数据包,向内向外都有效
2)无类队列的使用
无类队列的使用方法比较简单,TBF(Token Buffer Filter)是常用的一种队列,只是对数据包流量进行SHAPING,简单地限制网卡的流量。Linux下对流量进行限制的命令工具是tc,命令如下
1tc disc add dev eth1 root handle 1:0 tbf rate 128kbit burst 1000 latency 50ms
字段含义如下:
- tc disc add dev eth1表示在设备eth1上添加队列
- root表示根节点,没有父节点
- handle 1:0表示队列句柄
- tbf表示使用无类队列TBF
- rate 128kbit表示速度为128kbit
- burst 1000表示桶尺寸为1000
- latency 50ms表示数据包最多等待50ms
3)分类队列的使用
若需要对数据包进一步细分,对不同类型数据进行区别对待,分类队列就非常适合。CBQ(Class Based Queue)是一种比较常用的分类队列。在分类队列中多了类和过滤器两个概念,通过过滤器把数据包划分到不同的类里面,再递归地处理这些类。
场景:主机上物理网卡带宽100Mbit/s,主机上开启3个服务:ftp、snmp及http,对三种服务进行带宽限制
1//首先建立根队列
2tc disc add dev eth0 root handle 1:0 cbq bandwith 100Mbit avpkt 1000 cell 8
3//在此队列下建立三个类
4tc class add dev eht0 parent 1:0 classic 1:1 cbq bandwith 100Mbit rate 5 Mbit weight 0.5Mbit prio 5 cell 8 avpkt 1000
5tc class add dev eht0 parent 1:0 classic 1:2 cbq bandwith 100Mbit rate 10 Mbit weight 0.5Mbit prio 5 cell 8 avpkt 1000
6tc class add dev eht0 parent 1:0 classic 1:3 cbq bandwith 100Mbit rate 15 Mbit weight 0.5Mbit prio 5 cell 8 avpkt 1000
7//在三个类下建立队列或者对类进一步划分
8tc qdisc add dev eth0 parent 1:1 handle 10:0
9tc qdisc add dev eth0 parent 1:2 handle 20:0
10tc qdisc add dev eth0 parent 1:3 handle 30:0
11//最后再为根队列建立3个过滤器
12tc filter add dev eth0 parent 1:0 protocol ip prio 1 u32 math ip sport 20 0xfffff flowid 1:1
13tc filter add dev eth0 parent 1:0 protocol ip prio 1 u32 math ip sport 161 0xfffff flowid 1:2
14tc filter add dev eth0 parent 1:0 protocol ip prio 1 u32 math ip sport 80 0xfffff flowid 1:3
由此可见,我们为根队列创建了三个分类,分别对ftp、snmp及http这3种服务的数据包进行限制,其余数据包不受影响
4)在Docker中使用traffic controller
Docker通过veth pair技术创建一对虚拟网卡对时,一张放在宿主机网络环境中,一张放在容器的namespace里,若需要对容器对流量进行限制,那只需在宿主机的veth*网卡上进行流量限制,将traffic controller中的dev指定为veth*。若容器不需要在三层和四层间通信,指定icc参数可以禁止容器间直接通信。若需要容器之间进行通信或者对不同容器对流量进行限制,就需要预防同一台宿主机上容器之间进行DoS攻击,此时可以采用traffic controller容器对容器网卡流量进行限制,可以在一定程度上减轻DoS攻击危害。
(4)GRSecurity内核安全增强工具
Linux内核提供了namespaces来进行资源隔离,cgroups来限制容器的资源使用,但在内存安全问题上仍旧有许多问题,例如C/C++等非内存安全语言,并不会去检查数组的边界,程序可能会超越边界,而破坏相邻的内存区域,因此需要一些内存破坏的防御工作,去补充namespaces和cgroups。GRSecurity是一个对内核的安全拓展,通过智能访问控制来阻止内存破坏,预防0day漏洞等。
(5)fork炸弹
fork炸弹是一种利用系统调用fork(或其他等效方式)进行的服务阻断攻击的手段,以极快的速度创建大量进程(进程数呈以2为底数的指数增长趋势),并以此消耗系统分配予进程的可用空间使进程表饱和,从而使系统无法运行新程序。fork炸弹的应对从一开始就是很受社区关注,但现在的解决方案都不算完美。
- 通过ulimit限制最大进程数目:ulimit在Docker v1.6.0以上被支持,当调用fork创建进程,若该UID用户的进程数之和大于等于进程的RLIMIT_NPROC时,fork调用将会失败返回,但nproc是一个以用户为管理单位但设置选项,它调节的是一个用户UID的最大进程数之和,而默认情况下Docker在容器中启动的进程是root用户下的,umilit参数无法对超级用户进行限制
- 限制内核内存使用:fork炸弹的一大危害是它会消耗掉一系列的内核资源,例如进程表、内核内存等,其中内核内存资源永远保存在内存中而不会交换到swap区,所以fork炸弹可以轻而易举地形成对系统的DoS攻击。kmem(cgroup的memory.kmem.limit_in_bytes)可以限制内核内存资源,但也带来一些问题
- Docker还不支持直接配置memory.kmem.limit_in_bytes(PR #14006正在解决)
- kmem不仅是用来存储进程相关信息的,还保存了一些诸如文件系统相关、内核加密等内核数据,限制kmem可能影响其他正常操作
- Linux 4.0内核前的kmem实现存在泄漏问题
- cgroup pids子系统:Linux内核的一个开发中特性,允许用户配置在一定条件下拒绝fork调用、以及增加了任务计数器子系统等功能,从而完美解决fork炸弹问题