CAWProject
文章目录
实习、毕设、毕业、入职、找房子......在被这么多东西搞的焦头烂额后,终于有时间再来写一点关于毕设项目的东西了。
项目地址:CAWProject
项目的内容还是一个轻小说阅读器,但与之前做过的东西不同的地方在于~做了所有事情:抓取数据、API、客户端,做完的那一刻感觉一本满足(最近发现wenku8又诈尸了,只要输入以前的帐号密码,就能够登录,继续浏览,或许下次可以重新抓取一次试试,wenku8最大的优点就在于它丰富的插图了)。
工程主要分成三大部分:数据、服务端和客户端。
1.数据
(1)数据抓取
全部的数据都从sf小说的移动站点抓取:SF轻小说。得益于移动站点规范、简洁的设计,数据的抓取、格式化和建模都十分方便。数据相关的代码在Paersr文件下。
因为不熟悉爬虫,采用了最low的方式,全部下载到本地后再解析为格式化的JSON文本文件。
用shell写一个循环,然后把所有小说的简介页面,目录页面,章节页面全部下载下来了。
1for k in $(seq begin end)
2do
3 wget ....
4done
因为数量比较大,大约有4万多本小说,经过一次数据处理后,剩下26392本,目录页面与简介页面个数相同,章节页面更多,原始数据中页面个数接近60万,处理后剩下465834个。
按照简介 -> 目录 -> 章节 -> 封面与插图的顺序,处理了所有的数据。全部的HTML文件使用Ono解析,用XPath定位到数据,提取,存入JSONModel对象中,再保存到文件中。小说的简介数据全部存入MySQL,使用Objective-C连接MySQL,拼接成Insert语句后,瞬间插完。对于封面和插图数据,全部从处理后的JSON文本文件中全部提取到一个文件中,然后使用wget下载。
1wget -i urls.txt
虽然单线程下载速度较慢,但对于大量的数据来说,稳定比速度更重要,特别是我的macbook pro只有4GB的内存,所有数据都存在移动硬盘上,随时说爆就爆了。
处理后,全部的数据加起来大约13GB左右,接近整个SF轻小说移动站点的大小了。挂机一晚上就下载完了所有的HTML文件,在四核的iMac上,大约花上2分钟左右,就完成了数据格式化,最后从JSON文件里抽出所有图片链接,又挂机了一个晚上,全部下载完成。由于数据太大,GitHub上的项目中只上传了数据库文件,包含user与book两个表。
当一个文件夹下有数十万个文件时,用finder打开时,每次都会卡住,在终端里也不要尝试用tab键补全文件名或用ls列出文件,因为肯定会卡住,最好也关闭掉对文件数较多的文件夹的spotlight索引,不然mds_stores的写入量可以吓死人。
(2)chapterModel
项目里使用了很多的model,但没有一个比chapterModel更麻烦了,大多数的model只时单纯地存储数据,或者包含一些简单的处理逻辑,而chapterModel还包含了图文混排的逻辑(虽然内容只有.h文件),它对应的60多万个章节数据处理起来也是最麻烦的。
chapterModel.h文件的内容如下。
1@interface imageModel : JSONModel
2@property (nonatomic,strong) NSString *imageName;
3@property (nonatomic,assign) CGFloat width;
4@property (nonatomic,assign) CGFloat height;
5@end
6
7@protocol imageModel @end
8@interface chapterModel : JSONModel
9@property (nonatomic,assign) NSInteger cid;
10@property (nonatomic,strong) NSString *title;
11@property (nonatomic,strong) NSString *previous;
12@property (nonatomic,strong) NSString *index;
13@property (nonatomic,strong) NSString *next;
14@property (nonatomic,strong) NSArray *content;
15@property (nonatomic,strong) NSArray *images;
16@end
cid为章节ID,title为章节标题;
previous和next对应上一章节和下一章节的ID,当前章节为起始或末位章节时,则内容分别为
- header与footer;
- index对应章节所属目录的ID;
- content为包含文本内容的数组;
- images为包含图片模型的数据;
SF小说的阅读界面结构如下:
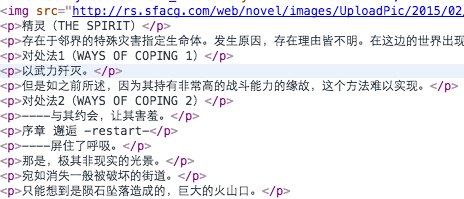
看到这样的结构,应该马上可以联想到数组,通过遍历数组,生成包含文本和插图的NSAttributedString,对于插图,可以预先存储其大小,让客户端优先完成排版,当图片下载完成时,再刷新插图。图片的占位符使用不可见字符 \u{FFFC},标识采用chapter-cid-imName的格式。
遍历content数组时,如果NSString对象含有chapter-cid前缀,则在images数组中查找匹配的对象,获取图片大小。但是由于许多图片不规范,需要缓存排版后的图片坐标,暂时还未启用这个加速分页的方法。
(3)小结
不知道哪一种方案更好,基本是这个过程中遇到的最大的问题,如果没有数据的话,App只是一个空壳,所以一开始的时间都投入到模型设计中,考虑App中每个界面可能用到哪些数据,并如何尽可能地利用已有的数据(毕竟我不生产数据,我只是数据的搬运工)。然而从网页上直接抓取的数据,有时候并不是十分规范,例如有些页面,把整本小说的内容,全部塞入简介中......不小心碰到时,就跪了。
2.服务端
(1)Swift、Python and AES
一开始为了方便,就选择使用Perfect框架来开发API,使用Swift编写,但基本上所有的操作都是处理请求、查数据库、返回数据还有加解密,Base64转换,因为还没有其他可以配套使用的工具,没办法尝试做缓存和负载均衡,部署到服务器上也很复杂,同时在我的macbook pro上运行iPhone模拟器和Perfect服务端时,内存十分紧张,所以后期使用Flask-RESTful来重写了接口,部署到服务器上也更加简单。服务端没有太多可以讲的内容,熟悉了接口编写的套路后,基本就在写业务逻辑了,从Swift迁移到Python时,唯一遇到的问题就是加解密的填充方式了。
AES是一种分组加密算法,对于原始数据分组中长度不足的部分,需要进行填充。由于CryptoSwift中默认使用了PKCS7的填充方式,加密等级与密钥长度相关,iOS自带的CommonCrypto也支持多种填充方式,然而Python自带的AES加解密工具中并没有预先进行填充的操作,需要自行实现,网上的一种实现如下:
1import binascii
2import StringIO
3class PKCS7Encoder(object):
4def __init__(self, k=16):
5 self.k = k
6
7 def decode(self, text):
8 nl = len(text)
9 val = int(binascii.hexlify(text[-1]), 16)
10 if val > self.k:
11 raise ValueError('Input is not padded or padding is corrupt')
12
13 l = nl - val
14 return text[:l]
15
16
17 def encode(self, text):
18 l = len(text)
19 output = StringIO.StringIO()
20 val = self.k - (l % self.k)
21 for _ in xrange(val):
22 output.write('%02x' % val)
23 return text + binascii.unhexlify(output.getvalue())
分别在加密前填充,解密前去除填充即可。
(2)小结
不论是采用Perfect还是Flask,能够提供稳定的服务才是关键,不过如果是在生产环境下的话,这两个貌似都没办法做到十分靠谱的程度,只是开发起来简单、迅速而够用,特别是这种毕设类型的......但在没有现成生产环境参考和熟悉的技术采纳时,Flask还是最佳的选择。
3.客户端
在连续写了两个Swift应用后,回头过来写Objective-C时,反而会有种不习惯的感觉,总的来说,Swift写起来比Objective-C更加爽快,缺点是混编时自动补全经常抽风,需要处理指针时十分麻烦,还有许多常用的第三方库都没有Swift版本,客户端的一些界面如下。
(1)界面展示
书架

个人中心
发现:目前存在内存泄漏,也许是因为做缩放效果导致的。


文库首页
搜索

小说简介
目录

最后是阅读器~又是一大波图,基本上一个阅读器该有的部分,全部都有了,只是bug较多。
图文混排的情况:图片做了圆角处理,尽可能占据屏幕。

菜单栏+字体、主题调整:延续了之前的18种主题,在图层上分别绘制文字和背景色,我最喜欢的还是羊皮纸。



目录+书签+文本检索


(2)阅读器
整个客户端工程中,阅读器模块的代码量是最大的,除了需要完成排版相关的操作外,还整合了多个界面,如同上面的截图所展示的,这一小节记录一些有意思的东西。
1)使用pop展示和隐藏view。
pop引擎不止可以用来制作动画,也可以用来展示和隐藏view,比起使用UIView动画,pop在逻辑上更加清晰,阅读器中多个不同的View分别对应着不同的controller来处理交互,但需要集中展示在阅读器中,使用pop让这些视图看起来如同存放在同一个场景下。
2)使用extension来分隔函数。
Swift中没有pragma标记,在controller比较庞大的时候,查找函数变得更加困难,extension可以用来分隔不同的功能,比如将不同的代理方法实现存放在不同的extension中,或者拓展selector,让target-action模式更加方便使用。
3)图文混排的简化。
图文混排的逻辑依旧是:
将文本与图片占位符存入到同一个NSMutableAttributedString中;
对于图片占位符,设置CTRunDelegate,主要就是提供图片尺寸大小,在合适范围内绘制对应的CTRun;
使用CoreText生成CTFrame,遍历CTFrame,获取图片在当前分页中的坐标;
在获得的坐标范围内绘制图片。
对于插图的坐标,基本就是一张图片占居一个CTRun,而这个CTRun又占据了所在的整个CTLine,所以只要获取到CTLine的Y轴坐标,再根据CTRunDelegate中设定的图片高度,就可以直接在该范围内绘制图片了,只有类似聊天消息中表情与文字混排的情况时,才需要获取到精确的CTRun所占据的Rect。
(3)小结
Swift是未来,虽然已经过了两年,但在很多方面,Swift没有Objective-C强大和稳定;
交互也存在于UI中,对于需要动起来的界面,设计的时候,需要想象力;
UICollectionView有着强大的自定义接口,例如阅读器、发现界面、书架和文库首页都是用它实现的,在一些场景下使用它来代替UITableView也不是不可能的;
设计比实现更加考验编程能力。