PostgreSQL笔记
文章目录
1. 前言
PostgreSQL作为博主技能清单的一项,本来也是在预计编写的博客中,但今天的面试中不出意料地还是问了MySQL相关的问题。但除了MySQL特有的一些问题外,那些没有复习到的数据库相关知识还是处于缺失的状态,这里结合一些出版图书和网上资料做一下笔记,完整复习一下数据库知识。
2. 为什么选择PostgreSQL?
没有为什么,在开始新项目时,通常是事后才考虑选择数据库管理系统。因为 loraserver 使用PostgreSQL,于是博主就与它保持一致。对于博主而言:
- 许多开源软件,例如mosquitto,都同时提供对MySQL和PostgreSQL的支持,在简单的数据库功能上两者其实是可相互替代的
- loraserver使用许多PostgreSQL特性,包括二进制类型、时间类型、GIN索引等,无法轻易迁移到MySQL
- loraserver中有许多PostgreSQL实践可以参考
- 使用同一种数据库可以减少开发、维护和运维的成本
那么 loraserver 为什么选择PostgreSQL呢?博主的观点如下:
- 两者都是开源软件,PostgreSQL是社区驱动,MySQL则由Oracle控制
- PostgreSQL支持更丰富的数据类型,包括二进制类型(物联网常用)、时间类型(用于GPS时间调度)、图形类型、网络地址、JSONB、UUID等,也可支持自定义类型
- PostgreSQL的MVCC实现中并发读写不阻塞,物联网环境下的协议层主要是数据采集,一般写多读少
- PostgreSQL有更好的拓展性,插件丰富,也有许多定制化开发,如时序数据库TimeScale
PostgreSQL和MySQL在性能、功能上一直处于相互追赶的状态,普遍的说法是前者偏向于学院风,比较多应用于科学研究、金融、物联网领域,后者偏向于互联网应用。从本质上来说:
- Postgres是对象关系数据库(ORDBMS),具有表继承和函数重载等功能,而MySQL是纯关系数据库(RDBMS)
- PostgreSQL功能丰富,可以处理复杂的查询和大型数据库,而MySQL更简单,相对易于设置和管理,快速、可靠且易于理解
但有意思的是,鉴于Oracle一贯的作风,MySQL被Oracle接手后,许多国外大厂直接开始了去MySQL化,例如Apple、Red Hat、Instagram就是以PostgreSQL代替MySQL。
3. 索引
PostgreSQL提供了B-Tree、Hash、GIN、GiST等多种索引类型,每种索引类型使用不同的算法来适应不同类型的查询。在默认情况下,创建的索引类型为B-Tree索引。
3.1 B-Tree
原理:
PostgreSQL包括了对标准B-Tree(多路平衡树)索引数据结构的一个实现。任何能够被排序为良定义线性顺序的数据结构都可以用一个btree来索引。唯一的限制是一个索引项不能超过大约三分之一个页面(如果适用,可以是TOAST压缩后的大小)。
适用场景:
- B-Tree索引可用于处理等值查询和范围查询,包括:<、<=、=、>=、>等运算符,BETWEEN、IN、IS NULL、IS NOT NULL等条件
- B-Tree索引可用于模式匹配查询,如“col LIKE′foo%′”或“col~′^foo′”,但是不能用于“col LIKE′%bar′”之类的后缀模糊匹配查询
- B-Tree索引还可以用于查询结果集排序,如ORDER BY排序
3.2 Hash
原理:src/backend/access/hash/README
Hash索引基于哈希表实现,只能用于等值查询。Hash索引根据每一行数据的索引字段计算哈希码,并维护哈希码、记录指针对应关系。对于哈希码相同的数据来说,可以采用链表来解决冲突。
适用场景:
- Hash索引存储的是被索引字段VALUE的哈希值,只支持等值查询
- Hash索引特别适用于字段VALUE非常长(不适合B-Tree索引)的场景,例如很长的字符串,并且用户只需要等值搜索
3.3 GIN
原理:
GIN表示通用倒排索引。GIN被设计为处理被索引项为组合值的情况,并且这种索引所处理的查询需要搜索出现在组合项中的元素值。
适用场景:需要搜索多值类型内的VALUE时,适合多值类型,例如数组、全文检索、TOKEN
3.4 GiST
原理:src/backend/access/gist/README
GiST表示通用搜索树,它是一种平衡的树结构的访问方法,可作为一种模板用来实现任意索引模式。
适用场景:
- 多维数据类型和集合数据类型
- 全文检索、几何数据类型
4. 事务
4.1 ACID特性
事务的四大特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),简称ACID特性。
- 原子性(Atomicity):事务包含的所有操作要么全部成功,要么全部失败回滚
- 一致性(Consistency):事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态
- 隔离性(Isolation):当多个用户并发访问数据库时(当操作同一个表时),数据库为每一个用户开启的事务,不能被其他事务的操作干扰,多个并发事务之间要相互隔离,关于事务的隔离性,数据库提供了多种隔离级别
- 持久性(Durability):事务一旦提交成功,那么它对数据库数据的改变将是永久性的
4.2 事务隔离级别
SQL标准定义了四种隔离级别,如下:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 序列化异常 |
|---|---|---|---|---|
| 读未提交(Read Uncommitted) | 可能(PG中不存在) | 可能 | 可能 | 可能 |
| 读已提交(Read Committed) | 不可能 | 可能 | 可能 | 可能 |
| 可重复读(Repeatable Read) | 不可能 | 不可能 | 可能(PG中不存在) | 可能 |
| 可序列化(Serializable) | 不可能 | 不可能 | 不可能 | 不可能 |
各个级别上被禁止出现的现象分别是:
- 脏读:在一个事务处理过程中读取了另一个未提交的事务中的数据
- 不可重复读:在一个事务范围内进行多次查询却返回了不同的数据,例如某一事务第2次查询时读取了另一个事务新提交的数据,特点是,针对已存在的记录,两次查询获取不同的记录值
- 幻读:在一个事务中,两次完全相同的查询获得不一样的结果集
- 序列化异常:成功提交一组事务的结果与这些事务所有可能的串行执行结果都不一致
PostgreSQL中只实现了三种不同的隔离级别,默认为读已提交(读未提交模式的行为与它一致),因为这是把标准隔离级别映射到PostgreSQL的MVCC架构的唯一合理方法。
4.3. 事务实现原理
事务的实现机制非常复杂,PostgreSQL使用回滚机制来实现事务的原子性,借助锁机制和MVCC机制来保证事务的并发性和隔离性,基于WAL、Checkpoint、Crash Recovery等机制实现事务的持久性,从而保证整个数据库系统始终处于一致性状态。
4.3.1 WAL
预写式日志(Write-Ahead Logging)是保证数据完整性的一种标准方法,WAL的核心机制是,数据文件(存储着表和索引)的修改必须在这些动作被日志记录之后才被写入。WAL机制的作用如下:
- 实现事务的持久性:每个事务在提交时先保证WAL日志已经刷写到硬盘文件中,这样即使数据库系统发生异常或重启,用户也可以通过回放(Replay)该事务的WAL日志进行恢复
- 支持数据库的灾难恢复:任何还没有被应用到数据页面的改变可以根据其日志记录重做(这是前滚恢复,也被称为REDO)
- 提升数据库性能:
- 将内存数据页的随机I/O转换为WAL日志文件的顺序I/O,降低事务提交时等待I/O的时延
- 在适当时机,被修改的内存数据页(脏页)由BgWriter进程或Checkpoint进程批量有序地刷写到硬盘中
WAL也用于一主多从架构中的流复制,主库不断发送 WAL数据,而每个备库接受WAL数据,并立即重放日志。
4.3.2 CheckPoint
Checkpoint机制是事务系列中的检查点,产生检查点时,所有的内存数据页都会被刷写到硬盘中,并且会在WAL日志中写入一条特殊的检查点记录,以确保在该检查点之前的所有信息都已经写到数据文件中了。
在数据库发生崩溃后,恢复过程会找到最后的检查点记录,然后重做这个检查点之后产生的事务日志,以便把数据库恢复到一致性状态(主要是保证事务的ACID特性)。
Checkpoint机制的作用如下:
- 保证数据库一致性,将缓冲区的脏数据写入硬盘,保证内存和硬盘中的数据是一致的
- 使WAL日志尽快失效,节省WAL日志所占用的硬盘空间
- 缩短数据库崩溃的恢复时间
PostgreSQL有几个参数可以决定Checkpoint检查点什么时候出现,如下:
- checkpoint_timeout:用来指定生成Checkpoint检查点最大的间隔时间
- checkpoint_completion_target:用来指定Checkpoint在时间上的完成目标
- max_wal_size:用来指定Checkpoint检查点之间允许生成的最大WAL日志的容量大小
当达到设置的checkpoint_timeout超时时间,或者WAL日志的max_wal_size已经被填满时,发起Checkpoint。
4.3.3 Crash Recovery
很多情况都会导致数据库服务进程异常终止,包括内存不足时被OOM Killer终止、操作系统崩溃、服务器停机、服务器重启、服务器发生硬件故障等。
Crash Recovery机制用于当数据库实例异常终止时,保障数据库能够从灾难中恢复到某个一致性状态。
PostgreSQL有以下4类文件用来保障故障的顺利恢复:
- WAL日志文件:记录事务日志
- 控制文件:记录Checkpoint等信息,该文件在global目录下,文件名为pg_control
- 数据文件:事务提交后,所做操作不必马上持久化,但Checkpoint检查点之前的数据必须持久化到数据文件中,当使用默认表空间时,所在目录为base/<dboid>
- 事务状态文件:记录每个事务的状态是提交还是回滚,该文件在pg_clog目录下
4.3.4 MVCC
PostgreSQL的并发控制机制同时实现两种协议,DML语句的并发控制将使用MVCC协议(Multi-Version Concurrency Control,MVCC),DDL语句的并发控制基于标准的两阶段封锁协议(Strict Two-Phase Locking,S2PL)。
多版本并发控制是一种并发控制的方法,用于实现数据库的并发访问。
使用MVCC机制的主要目的是:
- 让读操作不阻塞写操作,写操作不阻塞读操作,提升数据库访问的并发度
- 读操作访问行记录的最近一个版本,该版本是快照的一部分
- 写操作创建它们独有的隔离的行记录副本,用于更新
- 当两个写操作视图同时更新相同行记录时,才会出现使得事务阻塞的冲突
1. 事务ID
每当事务开始时,事务管理器就会为其分配一个称为事务标识(transaction id,txid)的唯一标识符。PostgreSQL的txid 是一个32位无符号整数,取值空间大小约为42亿。在事务启动后执行内置的txid_current()函数,即可获取当前事务的txid。
1testdb=> begin;
2BEGIN
3testdb=> select txid_current();
4 txid_current
5--------------
6 588461984
7(1 row)
8
9testdb=>
PostgreSQL保留三个特殊ID:
- 0:无效的txid
- 1:初始启动的txid,仅用于数据库集群的初始化过程
- 2:冻结的txid
txid在逻辑上无限,而实际使用32位长度保存(约42亿),PostgreSQL将txid空间视为一个环,对特定的txid,前21亿个txid属于过去,后21亿个txid属于未来。
2. 元组结构
源码:src/include/access/htup_details.h
1typedef struct HeapTupleFields
2{
3 TransactionId t_xmin; /* inserting xact ID */
4 TransactionId t_xmax; /* deleting or locking xact ID */
5
6 union
7 {
8 CommandId t_cid; /* inserting or deleting command ID, or both */
9 TransactionId t_xvac; /* old-style VACUUM FULL xact ID */
10 } t_field3;
11} HeapTupleFields;
12
13typedef struct DatumTupleFields
14{
15 int32 datum_len_; /* varlena header (do not touch directly!) */
16
17 int32 datum_typmod; /* -1, or identifier of a record type */
18
19 Oid datum_typeid; /* composite type OID, or RECORDOID */
20
21 /*
22 * datum_typeid cannot be a domain over composite, only plain composite,
23 * even if the datum is meant as a value of a domain-over-composite type.
24 * This is in line with the general principle that CoerceToDomain does not
25 * change the physical representation of the base type value.
26 *
27 * Note: field ordering is chosen with thought that Oid might someday
28 * widen to 64 bits.
29 */
30} DatumTupleFields;
31
32struct HeapTupleHeaderData
33{
34 union
35 {
36 HeapTupleFields t_heap;
37 DatumTupleFields t_datum;
38 } t_choice;
39
40 ItemPointerData t_ctid; /* current TID of this or newer tuple (or a
41 * speculative insertion token) */
42
43 /* Fields below here must match MinimalTupleData! */
44
45#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2
46 uint16 t_infomask2; /* number of attributes + various flags */
47
48#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3
49 uint16 t_infomask; /* various flag bits, see below */
50
51#define FIELDNO_HEAPTUPLEHEADERDATA_HOFF 4
52 uint8 t_hoff; /* sizeof header incl. bitmap, padding */
53
54 /* ^ - 23 bytes - ^ */
55
56#define FIELDNO_HEAPTUPLEHEADERDATA_BITS 5
57 bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
58
59 /* MORE DATA FOLLOWS AT END OF STRUCT */
60};
MVCC的核心机制是元组的可见性,PostgreSQL的元组用于表示某个记录行的一个快照版本,其中:
- t_xmin:保存产生此元组的事务的txid
- t_xmax:保存删除或更新此元组的事务的 txid,如果尚未删除或更新此元组,则t_xmax设置为0,即无效
- t_cid:保存命令标识(command id,cid),cid 的意思是在当前事务中,执行当前命令之前执行了多少SQL命令,从零开始计数
- t_ctid:保存着指向自身或新元组的元组标识符(tid)
3. 事务快照
源码:src/include/utils/snapshot.h
为了实现元组对事务的可见性判断,PostgreSQL引入了事务快照SnapshotData,具体数据结构如下:
1typedef struct SnapshotData
2 {
3 SnapshotType snapshot_type; /* type of snapshot */
4
5 /*
6 * The remaining fields are used only for MVCC snapshots, and are normally
7 * just zeroes in special snapshots. (But xmin and xmax are used
8 * specially by HeapTupleSatisfiesDirty, and xmin is used specially by
9 * HeapTupleSatisfiesNonVacuumable.)
10 *
11 * An MVCC snapshot can never see the effects of XIDs >= xmax. It can see
12 * the effects of all older XIDs except those listed in the snapshot. xmin
13 * is stored as an optimization to avoid needing to search the XID arrays
14 * for most tuples.
15 */
16 TransactionId xmin; /* all XID < xmin are visible to me */
17 TransactionId xmax; /* all XID >= xmax are invisible to me */
18
19 /*
20 * For normal MVCC snapshot this contains the all xact IDs that are in
21 * progress, unless the snapshot was taken during recovery in which case
22 * it's empty. For historic MVCC snapshots, the meaning is inverted, i.e.
23 * it contains *committed* transactions between xmin and xmax.
24 *
25 * note: all ids in xip[] satisfy xmin <= xip[i] < xmax
26 */
27 TransactionId *xip;
28 uint32 xcnt; /* # of xact ids in xip[] */
29
30 /*
31 * For non-historic MVCC snapshots, this contains subxact IDs that are in
32 * progress (and other transactions that are in progress if taken during
33 * recovery). For historic snapshot it contains *all* xids assigned to the
34 * replayed transaction, including the toplevel xid.
35 *
36 * note: all ids in subxip[] are >= xmin, but we don't bother filtering
37 * out any that are >= xmax
38 */
39 TransactionId *subxip;
40 int32 subxcnt; /* # of xact ids in subxip[] */
41 bool suboverflowed; /* has the subxip array overflowed? */
42
43 bool takenDuringRecovery; /* recovery-shaped snapshot? */
44 bool copied; /* false if it's a static snapshot */
45
46 CommandId curcid; /* in my xact, CID < curcid are visible */
47
48 /*
49 * An extra return value for HeapTupleSatisfiesDirty, not used in MVCC
50 * snapshots.
51 */
52 uint32 speculativeToken;
53
54 /*
55 * Book-keeping information, used by the snapshot manager
56 */
57 uint32 active_count; /* refcount on ActiveSnapshot stack */
58 uint32 regd_count; /* refcount on RegisteredSnapshots */
59 pairingheap_node ph_node; /* link in the RegisteredSnapshots heap */
60
61 TimestampTz whenTaken; /* timestamp when snapshot was taken */
62 XLogRecPtr lsn; /* position in the WAL stream when taken */
63 } SnapshotData;
事务快照是用来存储数据库的事务运行情况,一个事务快照的创建过程可以概括为:
- 查看当前所有的未提交并活跃的事务,存储在数组中
- 选取未提交并活跃的事务中最小的XID,记录在快照的xmin中
- 选取所有已提交事务中最大的XID,加1后记录在xmax中
- 根据不同的情况,赋值不同的satisfies,创建不同的事务快照
根据xmin和xmax的定义,事务和快照的可见性可以概括为:
- 当事务ID小于xmin的事务表示已经被提交,其涉及的修改对当前快照可见
- 事务ID大于或等于xmax的事务表示正在执行,其所做的修改对当前快照不可见
- 事务ID处在 [xmin, xmax)区间的事务, 需要结合活跃事务列表与事务提交日志CLOG,判断其所作的修改对当前快照是否可见,即SnapshotData中的satisfies
示例:
1testdb=> begin;
2BEGIN
3testdb=> select txid_current_snapshot();
4 txid_current_snapshot
5-----------------------
6 588519052:588519055:588519052, 588519054
7(1 row)
8
9testdb=> end;
10COMMIT
11testdb=>
txid_current_snapshot的文本表示是xmin:xmax:xip_list,其中:
- xmin:最早仍然活跃的事务的txid,所有比它更早的事务(txid <xmin),要么已经提交并可见,要么已经回滚并生成死元组
- xmax:第一个尚未分配的txid。所有txid ≥ xmax的事务在获取快照时尚未启动,因此其结果对当前事务不可见
- xip_list:获取快照时活跃事务的txid列表。该列表仅包括xmin与xmax之间的txid
4. 隔离级别的实现
PostgreSQL中根据获取快照时机的不同实现了不同的数据库隔离级别
- 读未提交/读已提交:每个query都会获取最新的快照CurrentSnapshotData
- 可重复读:所有的query 获取相同的快照都为第1个query获取的快照FirstXactSnapshot
- 可序列化:使用锁系统来实现
PostgreSQL的MVCC实现方法有利有弊。其中最直接的问题就是表膨胀,为了解决这个问题引入了AutoVacuum自动清理辅助进程,将MVCC带来的垃圾数据定期清理。
4.3.5 锁机制
确保隔离性的方法之一是,对数据记录以互斥的方式进行访问。PostgreSQL包含了两个级别的锁:表锁和行锁。
1. 表锁
表锁模式:
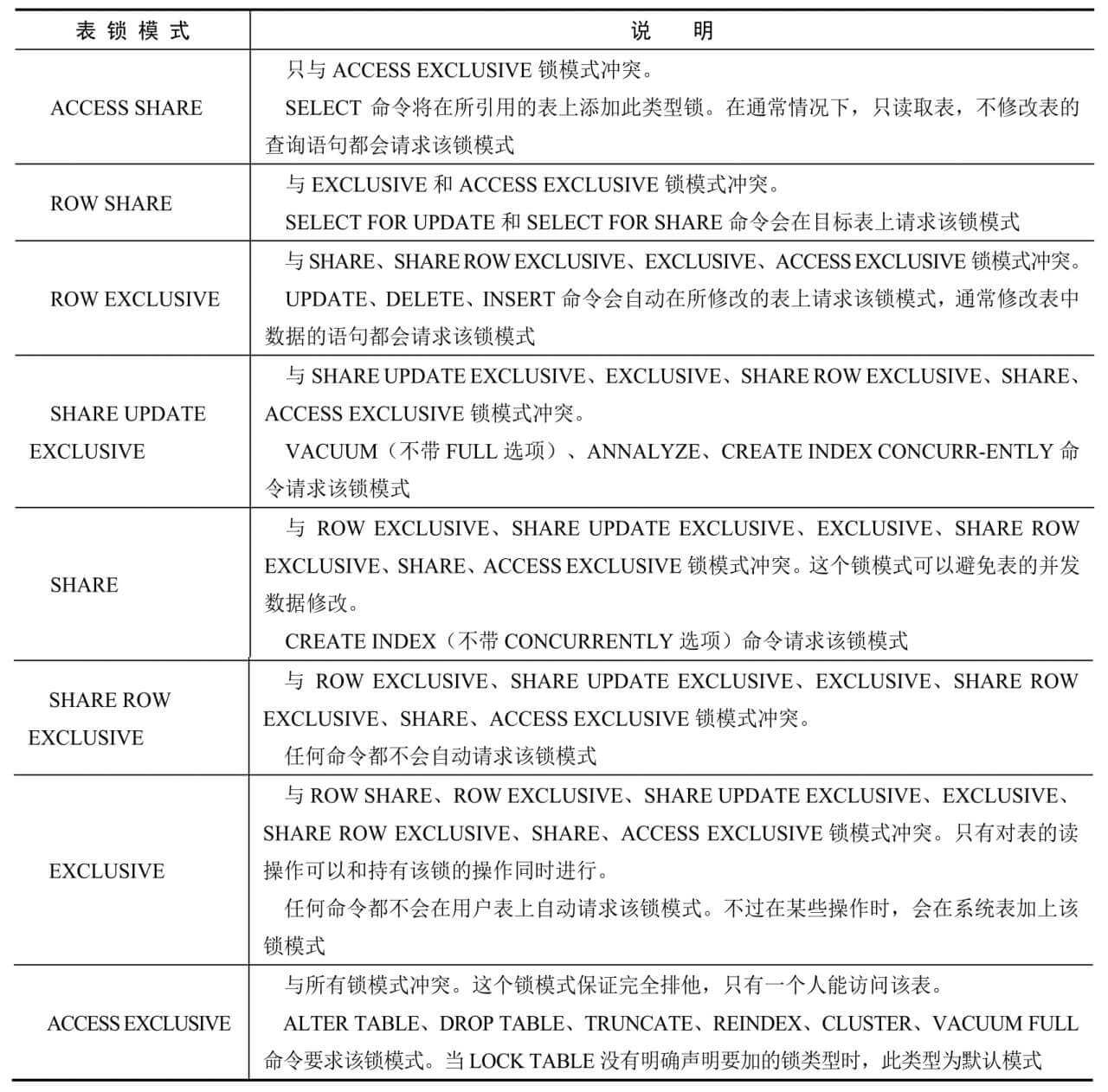
冲突的锁模式:
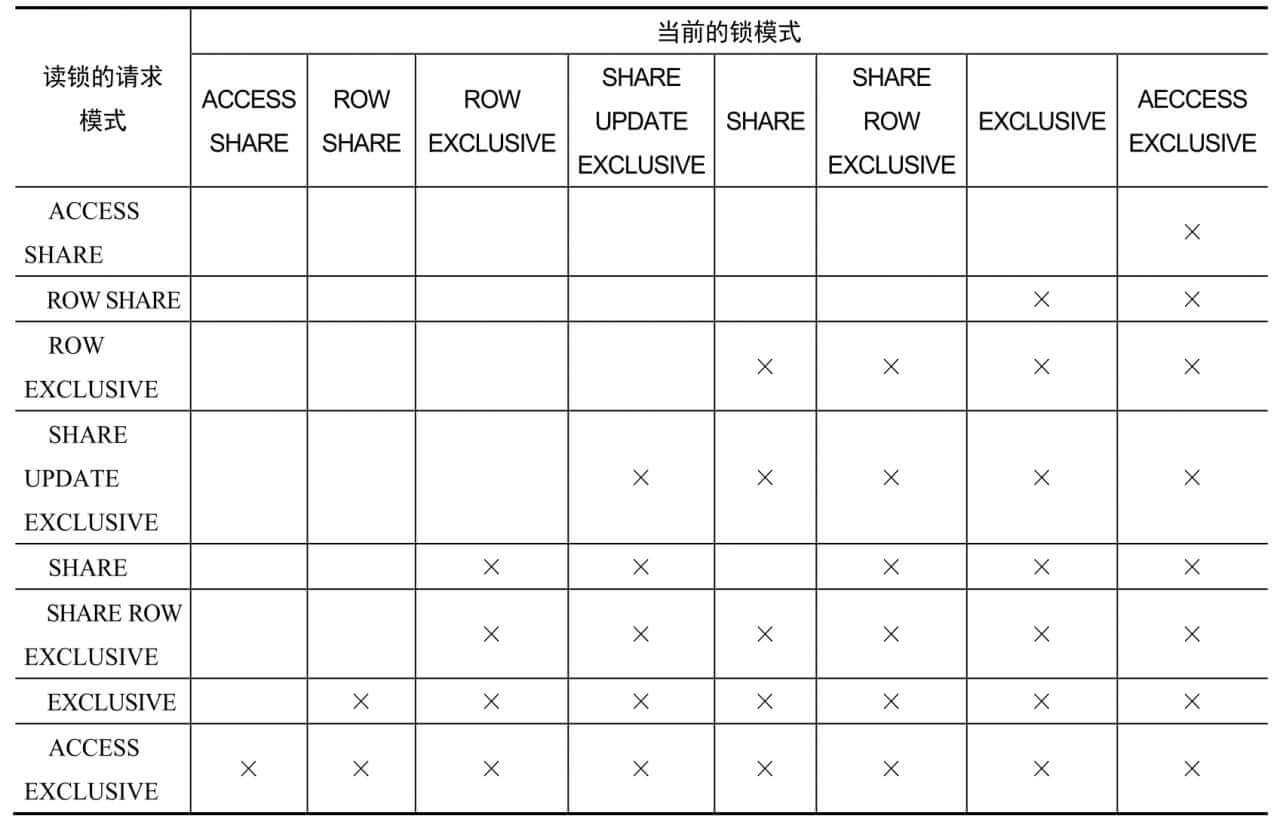
2. 行锁
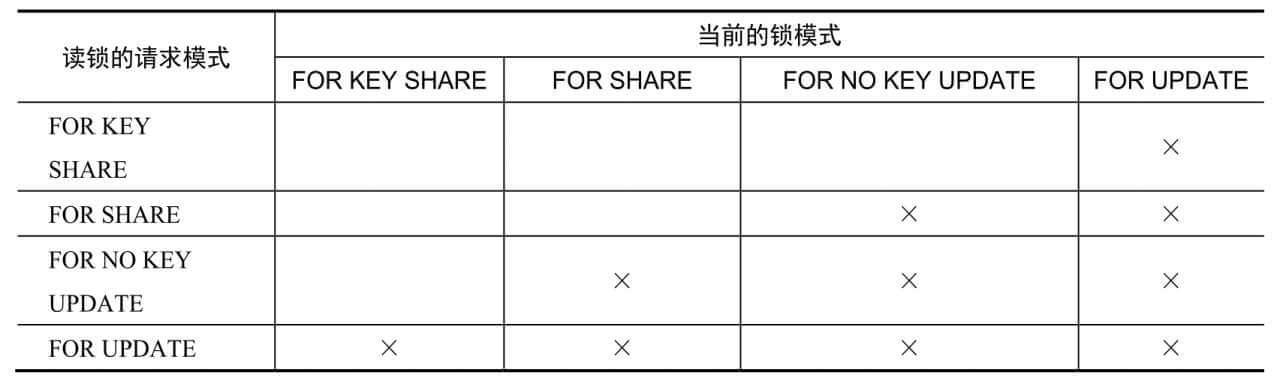
行锁模式:
- FOR UPDATE:FOR UPDATE会导致由SELECT命令检索到的行被锁定,就好像它们要被更新。这可以阻止它们被其他事务锁定、修改或删除,一直到当前事务结束
- FOR NO KEY UPDATE:FOR NO KEY UPDATE与FOR UPDATE的行为类似,不过获得的锁较弱,这种锁不会阻塞尝试在相同行上获得锁的SELECT FOR KEYSHARE命令
- FOR SHARE:FOR SHARE与FOR NO KEY UPDATE的行为类似,不过它在每个检索到的行上获得一个共享锁而不是排他锁
- FOR KEY SHARE:FOR KEY SHARE与FOR SHARE的行为类似,不过获得的锁较弱,SELECT FOR UPDATE命令会被阻塞,但是SELECT FOR NO KEY UPDATE命令不会被阻塞
冲突的行锁:
5. 高可用方案
5.1 流复制
PostgreSQL流复制主要有两种模式:同步流复制和异步流复制,区别如下:
同步流复制模式
在同步流复制模式中,主库上提交的事务会等待至少一个备库接收WAL日志流并发回确认信息后主库才向客户端返回成功,因此同步流复制模式下主库、备库的数据理论上是完全一致的,这种模式下高可用方案只需提供一个VIP(virtual ip)做高可用IP,通常这个VIP绑定在主库主机上,当主库异常时,将VIP飘移到备库主机上即可,同步流复制写性能损耗较大,生产环境很少使用同步流复制环境,特别是只有一主一备的环境,因为同步流复制备库宕机时,主库的写操作将被阻塞,相当于多了一个故障点。
异步流复制模式
在异步流复制模式中,主库上提交的事务不会等待备库接收WAL日志流并发回确认信息后主库才向客户端返回成功,因此异步流复制模式下主库、备库的数据存在一定延迟,延迟的时间受主库压力、主备库主机性能、网络带宽影响,当主库不是很忙并且主备库主机压力不是很大时,主备数据延迟通常能在毫秒级,因此,基于异步流复制制定高可用方案时需要考虑主备数据延迟的因素,例如可以设置一个主备延迟阀值,当主库宕机时,只有当备库的延迟时间在指定阀值内才做主备切换,这方面属于主备切换规则问题,可根据实际应用场景进行定义设置。
5.2 高可用架构
- PostgreSQL异步流复制+keepalived
- PostgreSQL异步流复制+pgpool
- PostgreSQL同步流复制+共享存储
- PG-X系列
6. 分布式方案
6.1 分布式理论基础
CAP理论提出了一致性、可用性、分区容忍性的取舍问题;Paxos、Raft、2PC、3PC分别给出了一致性的解决方案;Lease机制主要针对网络拥塞或瞬断的情况下,出现双主情况的解法;Quorum NWR和MVCC主要解决分布式存储领域的一致性问题;Gossip是一种去中心化、容错而又最终一致性的算法。
6.1.1 CAP理论
分布式系统的CAP理论:首先将分布式系统中的三个特性进行如下归纳
- Consistency(一致性):在分布式系统中的所有数据备份,在同一时刻是否有同样的值。(等同于所有节点访问同一份最新的数据副本)
- Availability(可用性):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
- Partition tolerance(分区容忍性):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在一定时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
高可用、数据一致是很多系统设计的目标,但是分区又是不可避免的事情,由此引出了以下几种选择:
- CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的,典型放弃分区容忍性的例子有单点关系型数据库、LDAP
- CP without A:如果不要求A(可用性),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的,例如很多传统的数据库分布式事务、分布式锁
- AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性,例如众多的NoSQL、DNS和Web缓存
6.1.2 PAXOS
Paxos协议是一个解决分布式系统中,多个节点之间就某个值(提案)达成一致(决议)的通信协议。它能够处理在少数节点离线的情况下,剩余的多数节点仍然能够达成一致。
6.1.3 Raft
Raft提供了和Paxos算法相同的功能和性能,但是它的算法结构和Paxos不同。Raft算法更加容易理解并且更容易构建实际的系统。为了提升可理解性,Raft将一致性算法分解成了几个关键模块,例如领导人选举、日志复制和安全性。同时它通过实施一个更强的一致性来减少需要考虑的状态的数量。Raft算法还包括一个新的机制来允许集群成员的动态改变,它利用重叠的大多数来保证安全性。
6.2 分布式架构
6.2.1 Citus
Citus以插件的方式扩展到PostgreSQL中,独立于PostgreSQL内核,所以能很快的跟上PostgreSQL主版本的更新,部署也比较简单。
Citus节点主要分为协调节点(Coordinator)和工作节点(Worker),协调节点不存储真实数据,只存储数据分布的元信息,实际的数据被分成若干分片,打散到不同工作节点中,应用连接协调节点进行SQL解析,生成分布式执行计划,下发到工作节点执行,执行结果由协调节点汇总返回客户端。
6.2.2 Greenplum
Greenplum是面向数据仓库应用的关系型数据库,是一种基于MPP(大规模并行处理)架构和Postgres开源数据库技术的大数据技术,每个计算机群集都包含一个主节点,备用主节点和段节点。所有数据都驻留在段节点上,目录信息存储在主节点上。段节点运行一个或多个段,这些段是已修改的PostgreSQL数据库实例,并分配有内容标识符。对于每个表,数据都是根据用户在数据定义语言中指定的分布列关键字在段节点之间划分的。对于每个段内容标识符,既有主段又有镜像段,它们不在同一物理主机上运行。当查询进入主节点时,将对其进行分析,计划和调度,将其分配给所有段以执行查询计划,然后返回请求的数据或将查询的结果插入数据库表中。
7. 参考资料
- 《深入浅出PostgreSQL》
- 《PostgreSQL实战》
- 《PostgreSQL指南:内幕探索》
- PgSQL · 应用案例 · PostgreSQL 9种索引的原理和应用场景
- PostgreSQL 11.2 手册
- PgSQL · 特性分析 · MVCC机制浅析
- 浅谈PostgreSQL高可用架构