TCP协议笔记-01
文章目录
1. 前言
杨师傅说过,要掌握一门协议,就必须往下探一层,凡事究其本质,道理都是相通的。
遗憾的是博主没有基于TCP设计过协议,对IP层的了解也只限于iptables,更熟悉是贴近硬件的数据链路层协议:LoRaWAN,应用层则是MQTT和Websocet。
从已有的知识来看待TCP,和LoRaWAN类似,设计传输协议时,至少做到
- 可靠性:确认机制+重传,LoRaWAN使用一问一答的机制+上下行帧计数器+MIC,TCP采用滑动窗口的机制+发送序列号+确认序列号+校验和
- 稳定性:自适应速率,LoRaWAN采用的是ADR机制(我们使用卡尔曼滤波实现),TCP采用了多种拥塞调度算法
除此之外,还需要考虑效率,安全等等。虽然LoRaWAN在OSI模型中跟传输层相差甚远,但它和TCP一样都是二进制协议,后面的笔记中还会继续使用它来做类比。不过想要阅读和理解TCP还存在一个问题:TCP协议栈位于内核,必须从操作系统代码入手。
总的来说难度系数比较大,所以还是按处理未知问题的老套路,先穷举出可用可配置的部分,再去探究底层实现。
2. 报文格式与套接字
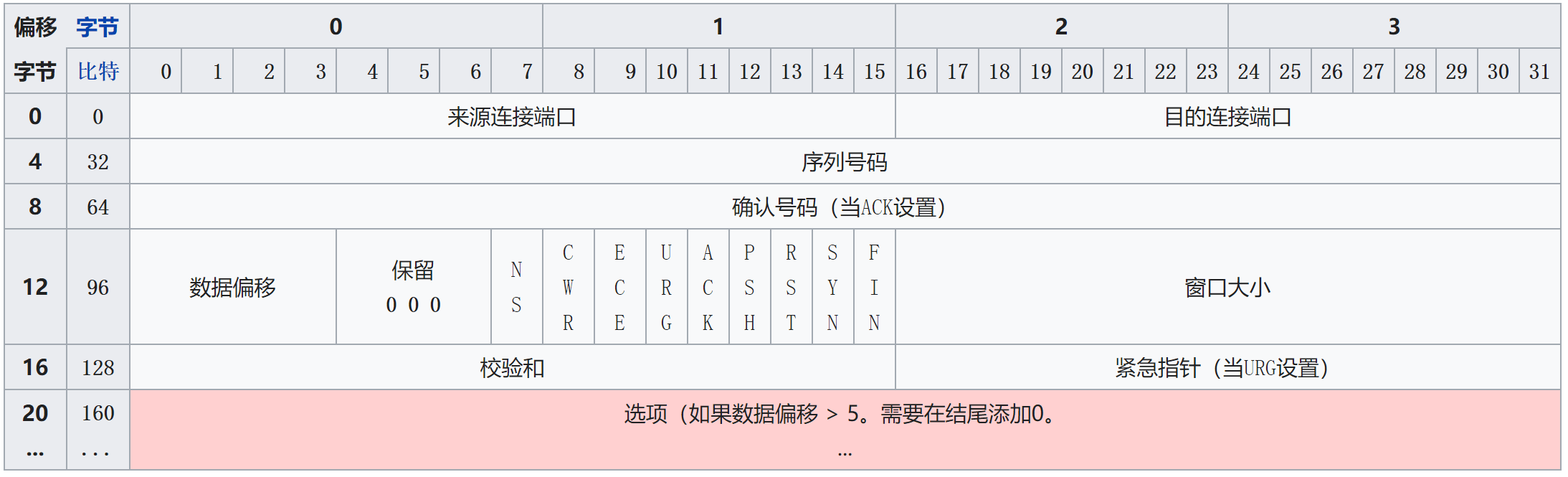
- TCP协议的固定头部长度为20字节,选项字段最长40字节,即TCP头部最短20字节,最长60字节
- 来源端口号和目标端口号,16位
- 序列号,32位,随机初始化,使用过程中递增,溢出后回滚,也就是说在一个TCP连接上传输4GB流量后,必然产生回滚,此外
- 若SYN标志置位,则表示初始序列号,实际数据的第一个字节的序列号和相应ACK中的确认号就是该序列号加1
- 若SYN标志位没有置位,则表示当前会话中该段的第一个数据字节的累积序列号
- 确认号,32位,ACK标志置位时有效,数值为发送方期望的下一个序列号,且表示确认接收了该序列号之前的所有数据
- 数据偏移,4位长,取值5~15,单位4字节,表示TCP段起始位置到实际数据的偏移
- 保留位,3位长,必须置0
- 标志位,9位长
- NS:ECN-nonce,ECN显式拥塞通知(Explicit Congestion Notification)是对TCP的扩展,定义于RFC 3540。ECN允许拥塞控制的端对端通知而避免丢包。
- CWR:Congestion Window Reduced,定义于RFC 3168
- ECE:ECN-Echo有两种意思,取决于SYN标志的值,定义于RFC 3168
- URG:表示紧急指针字段有效
- ACK:表示确认字段有效,客户端发送的初始SYN数据包之后的所有数据包都应设置此标志
- PSH:推送标志,要求将缓冲的数据推送到接收数据的应用程序
- RST:重置连接
- SYN:同步序列号,从两端发送的第一个数据包应设置此标志,其他一些标志和字段会根据此标志更改含义,一些仅在设置时有效,一些则在清除时有效
- FIN:表示来自发送方的最后一个数据包
- 窗口大小,16位长,表示从确认号开始,本报文的发送方可以接收的字节数,即接收窗口大小,用于流量控制
- 校验和,16位长,对整个的TCP报文段,进行计算所得
- 紧急指针,16位长,URG标志置位时有效,表示最后一个紧急数据字节相对序列号的偏移量
- 选项字段:最多40字节,必须能被4整除,长度取决于数据偏移大小。每个选项最多三个字段:类型(1字节)、长度(1字节,可选)、数据(可选)。
- 0:选项列表结束,长度8位,无数据段
- 1:无操作(NOP,填充),长度8位,无数据段,用于选项字段之间的字边界对齐,提高性能
- 2:最大分段大小(MSS,Maximum Segment Size),长度32位,例如:0x02 0x04 0x05B4,通常在创建连接而设置SYN标志的数据包中指明这个选项,指明本端所能接收的最大长度的报文段。通常将MSS设置为(MTU-40)字节,携带TCP报文段的IP数据报的长度就不会超过MTU(MTU最大长度为1518字节,最短为64字节),从而避免本机发生IP分片,配合SYN使用
- 3:窗口缩放因子,长度24位,配合SYN使用
- 4:选择性确认(SACK),长度16位,表示发送端支持并同意使用SACK选项,配合SYN使用
- 5:SACK实际工作的选项,长度位10、18、26或34位
- 8:时间戳,长度80位,包含发送端的时间戳(Timestamp Value)和时间戳回显应答(Timestamp Echo Reply),用于解决TCP序列号回滚
- 填充:TCP报头填充,确保TCP报头的起始和结束都以32位长度对齐,填充由0组成
对比LoRaWAN
- TCP在序列号上使用的是当前会话中该段的第一个数据字节的累积序列号,是数据流的概念,而LoRaWAN的序列号使用的是计数器,每发一个包则递增一次,因此产生了不同的确认机制
- TCP中客户端接收到确认序列号时,表示服务端确认接收该序列号以前的所有字节流,可实现累积确认,而LoRaWAN的确认机制只能一包一包执行,除非在应用层自行实现累积确认或批量确认
- 数据偏移、变长字、标志位等的设计大同小异,不过奇怪的是变长数据通常以TLV形式组织,即tag、length、value,LoRaWAN的定义中length表示value长度,而TCP选项字段中length表示单个选项的总长度
- TCP使用校验和的机制,而LoRaWAN采用端到端的校验,使用AES算法,结合密钥、原始数据、32位帧计数器生成MIC
TCP套接字的使用就比较简单,因为系统只提供了比较有限的参数配置,下面分别是Go版本的示例代码,只实现了半双工的模式,要实现全双工的话,每个连接需要两个goroutine来维护,同时做好并发控制。
客户端
1package main
2
3import (
4 "context"
5 "log"
6 "net"
7 "time"
8 "fmt"
9)
10
11func main() {
12 var d net.Dialer
13 ctx, cancel := context.WithTimeout(context.Background(), time.Minute)
14 defer cancel()
15
16 conn, err := d.DialContext(ctx, "tcp", "localhost:12345")
17 if err != nil {
18 log.Fatalf("Failed to dial: %v", err)
19 }
20 defer conn.Close()
21 fmt.Println("conn established: ", conn)
22 if _, err := conn.Write([]byte("Hello, World!")); err != nil {
23 log.Fatal(err)
24 }
25 reply := make([]byte, 512)
26 n, err := conn.Read(reply)
27 if err != nil {
28 log.Fatal(err)
29 }
30 log.Printf("received %q (%d bytes)\n", string(reply[:n]), n)
31}
服务端
1package main
2
3import (
4 "io"
5 "log"
6 "net"
7 "fmt"
8)
9
10func main() {
11 // Listen on TCP port 12345 on all available unicast and
12 // anycast IP addresses of the local system.
13 l, err := net.Listen("tcp", ":12345")
14 if err != nil {
15 log.Fatal(err)
16 }
17 defer l.Close()
18 for {
19 // Wait for a connection.
20 conn, err := l.Accept()
21 if err != nil {
22 log.Fatal(err)
23 }
24 fmt.Println("new conn: ", conn)
25 // Handle the connection in a new goroutine.
26 // The loop then returns to accepting, so that
27 // multiple connections may be served concurrently.
28 go func(c net.Conn) {
29 // Echo all incoming data.
30 io.Copy(c, c)
31 fmt.Println("close conn: ", conn)
32 // Shut down the connection.
33 c.Close()
34 }(conn)
35 }
36}
如果将conn转换为TCPConn,会多一些可配置的方法,但也无法干涉到一些具体操作,主要还是通过配置内核参数来控制TCP
1// CloseRead shuts down the reading side of the TCP connection.
2// Most callers should just use Close.
3func (c *TCPConn) CloseRead() error {
4 if !c.ok() {
5 return syscall.EINVAL
6 }
7 if err := c.fd.closeRead(); err != nil {
8 return &OpError{Op: "close", Net: c.fd.net, Source: c.fd.laddr, Addr: c.fd.raddr, Err: err}
9 }
10 return nil
11}
12
13// CloseWrite shuts down the writing side of the TCP connection.
14// Most callers should just use Close.
15func (c *TCPConn) CloseWrite() error {
16 if !c.ok() {
17 return syscall.EINVAL
18 }
19 if err := c.fd.closeWrite(); err != nil {
20 return &OpError{Op: "close", Net: c.fd.net, Source: c.fd.laddr, Addr: c.fd.raddr, Err: err}
21 }
22 return nil
23}
24/ SetLinger sets the behavior of Close on a connection which still
25// has data waiting to be sent or to be acknowledged.
26//
27// If sec < 0 (the default), the operating system finishes sending the
28// data in the background.
29//
30// If sec == 0, the operating system discards any unsent or
31// unacknowledged data.
32//
33// If sec > 0, the data is sent in the background as with sec < 0. On
34// some operating systems after sec seconds have elapsed any remaining
35// unsent data may be discarded.
36func (c *TCPConn) SetLinger(sec int) error {
37 if !c.ok() {
38 return syscall.EINVAL
39 }
40 if err := setLinger(c.fd, sec); err != nil {
41 return &OpError{Op: "set", Net: c.fd.net, Source: c.fd.laddr, Addr: c.fd.raddr, Err: err}
42 }
43 return nil
44}
45
46// SetKeepAlive sets whether the operating system should send
47// keep-alive messages on the connection.
48func (c *TCPConn) SetKeepAlive(keepalive bool) error {
49 if !c.ok() {
50 return syscall.EINVAL
51 }
52 if err := setKeepAlive(c.fd, keepalive); err != nil {
53 return &OpError{Op: "set", Net: c.fd.net, Source: c.fd.laddr, Addr: c.fd.raddr, Err: err}
54 }
55 return nil
56}
57
58// SetKeepAlivePeriod sets period between keep-alives.
59func (c *TCPConn) SetKeepAlivePeriod(d time.Duration) error {
60 if !c.ok() {
61 return syscall.EINVAL
62 }
63 if err := setKeepAlivePeriod(c.fd, d); err != nil {
64 return &OpError{Op: "set", Net: c.fd.net, Source: c.fd.laddr, Addr: c.fd.raddr, Err: err}
65 }
66 return nil
67}
68
69// SetNoDelay controls whether the operating system should delay
70// packet transmission in hopes of sending fewer packets (Nagle's
71// algorithm). The default is true (no delay), meaning that data is
72// sent as soon as possible after a Write.
73func (c *TCPConn) SetNoDelay(noDelay bool) error {
74 if !c.ok() {
75 return syscall.EINVAL
76 }
77 if err := setNoDelay(c.fd, noDelay); err != nil {
78 return &OpError{Op: "set", Net: c.fd.net, Source: c.fd.laddr, Addr: c.fd.raddr, Err: err}
79 }
80 return nil
81}
3. 握手
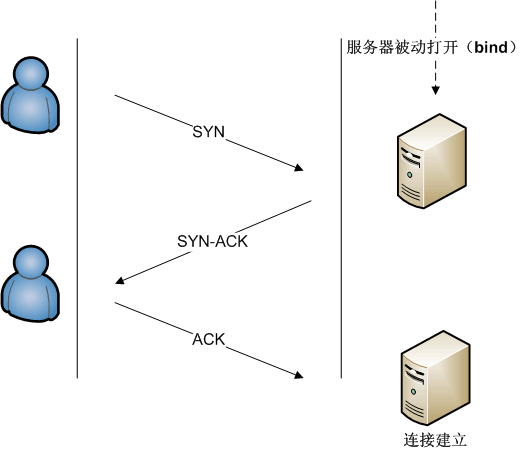
LoRaWAN是面向数据报的协议,使用上更接近UDP,而TCP是面向字节流的协议,每次使用都必须先建立连接,而握手过程两者是类似的。
由于底层还是使用不可靠的IP协议,那么意味者每个握手包都有可能丢失,由此可以衍生出TCP握手过程中的不同状态。
在同一子网下,通讯双方都可以主动发起握手,这里以主动发起握手的一方作为客户端为例。
3.1 客户端发送SYN(seq=i)包
客户端发送SYN包后,进入 SYN-SENT 状态,若链路正常,则收到服务端SYN+ACK,假设丢包率100%,有两种可能
- 客户端的SYN包未到达服务端
- 服务端的SYN+ACK包未到达客户端
两种情况下,客户端都无法进入下一阶段,会执行重发,重发次数由 net.ipv4.tcp_syn_retries 参数控制,可以通过两个命令获取该参数
1sysctl net.ipv4.tcp_syn_retries
2cat /proc/sys/net/ipv4/tcp_syn_retries
CentOS 7上输出的是6,最坏情况下尝试6次重发,发送间隔依次翻倍,最多耗时约127秒(其实发送间隔的单位是RTO,初始时设置为1秒,传输过程中RTO由SRTT+SRTT系数计算,是动态变化的)。
总结有以下场景
- No route to host:若服务端IP不可达,会直接报错
- Connection refused:若服务端IP可达,但是该端口未启动服务,则服务端响应RST数据包,重置连接
- Connection timed out:若服务端IP可达,但由于各种情况导致客户端无法接收任何回包直至超时
3.2 服务端响应SYN+ACK(seq=j,ack=i+1)包
服务端接收到SYN包后,就会响应SYN+ACK包,进入 SYN-RECEIVED 状态,等待客户端回包。假设丢包率100%,有两种可能
- 服务单的SYN+ACK包未到达客户端
- 客户端的SYN+ACK包未到达服务端
两种情况下,服务端都无法进入下一阶段,会执行重发,由 net.ipv4.tcp_synack_retries 参数控制,可以通过两个命令获取该参数
1sysctl net.ipv4.tcp_synack_retries
2cat /proc/sys/net/ipv4/tcp_synack_retries
CentOS 7上输出的是5,最坏情况下尝试5次重发,发送间隔依次翻倍,最多耗时约63秒。
网络上常见的SYN攻击就是在这一步产生的,服务器响应SYN+ACK后,会将该连接放入SYN队列,客户端回复ACK后,该连接转移到ACCEPT队列。如果客户端未回复ACK,该连接会一直等待到超时后才会从队列中移除。
SYN队列长度由 net.ipv4.tcp_max_syn_backlog 参数控制,可以通过两个命令获取该参数
1sysctl net.ipv4.tcp_max_syn_backlog
2cat /proc/sys/net/ipv4/tcp_max_syn_backlog
我们在服务端创建监听时,也会传入一个backlog参数,它设置的是ACCEPT队列长度,该队列长度受到 net.core.somaxconn 参数限制,Golang不支持手动设置backlog长度,net包在创建监听时,其实是读取 /proc/sys/net/core/somaxconn 获取系统默认backlog。但 Cloudflare的博客 提到过,现在的内核中,SYN队列长度也会受到 /proc/sys/net/core/somaxconn 的限制。
除上述参数外,服务端还有一个 net.ipv4.tcp_syncookies 参数可配置,若该参数设置为1,当出现SYN队列溢出时,启用cookie(对客户端IP地址、端囗,服务器IP地址、端口等等进行hash运算,加密得到)回复客户端,收到客户端ACK后再进行校验,防范少量的SYN攻击。
3.3 客户端响应ACK(seq=i+1,ack=j+1)包
客户端接收到服务器SYN+ACK包后,就会响应ACK包,自己进入 ESTABLISHED 状态,认为连接可用。客户端此时可以开始发送数据,但在服务端连接进入 ESTABLISHED 状态前,服务端用户层是不会收到任何数据的。
如果服务端没有收到回包,则会继续发送SYN+ACK,客户端也会响应ACK包。
如果服务端收到了回包,连接进入 ESTABLISHED 状态,此时该连接从SYN队列移入ACCEPT队列,如果及时调用了ACCEPT函数,该连接会从ACCEPT队列中移出,用户获取到一个可通信的连接。
在最后一步产生丢包且服务器处于补发过程时,客户端将持续接收到服务器的SYN+ACK包。现在能够产生丢包的情况只有 客户端的ACK包未到达服务端,也可以区分为两种情况:
- 第三次握手的ACK数据包未到达服务端,若客户端及时发送数据,产生PSH+ACK包,也可帮助服务器完成连接建立
- 所有带ACK标志的数据包都未到达服务端
握手的前两步中,一旦服务器应答SYN+ACK,且产生丢包,则双方都会重发,导致抓包结果比较混乱,我们可以在这一步再进行限制来模拟丢包。
我们可以在客户端上创建防火墙规则来限制数据流出,达到模拟的效果。
对于第一种情况,iptables指令如下:
1iptables -A OUTPUT -p tcp --tcp-flags ALL ACK --dport 12345 -j DROP
该指令将拦截所有目标端口为12345的流出ACK数据包,只干涉第三次握手,若及时发送数据,也可完成连接建立。
对于第二种情况,我们需要再增加一条指令,如下:
1iptables -A OUTPUT -p tcp --tcp-flags ALL PSH,ACK --dport 12345 -j DROP
该指令将拦截所有目标端口为12345的流出PSH+ACK数据包,在第三次握手丢失后,即使有数据发送,也会被拦截。
我们可以在Linux环境下使用tcpdump工具导出cap文件,然后在wireshark中查看。
4. 挥手
下图是一个根据示例代码抓包得到的三次握手和三次挥手:

示例代码中,当客户端发起挥手时,服务器也立刻关闭连接,因此FIN+ACK请求收到了一个FIN+ACK的应答,最后客户端回复ACK结束连接。如果在执行Close前做了一些耗时操作,那么三次挥手就会被拆解成标准的四次挥手。
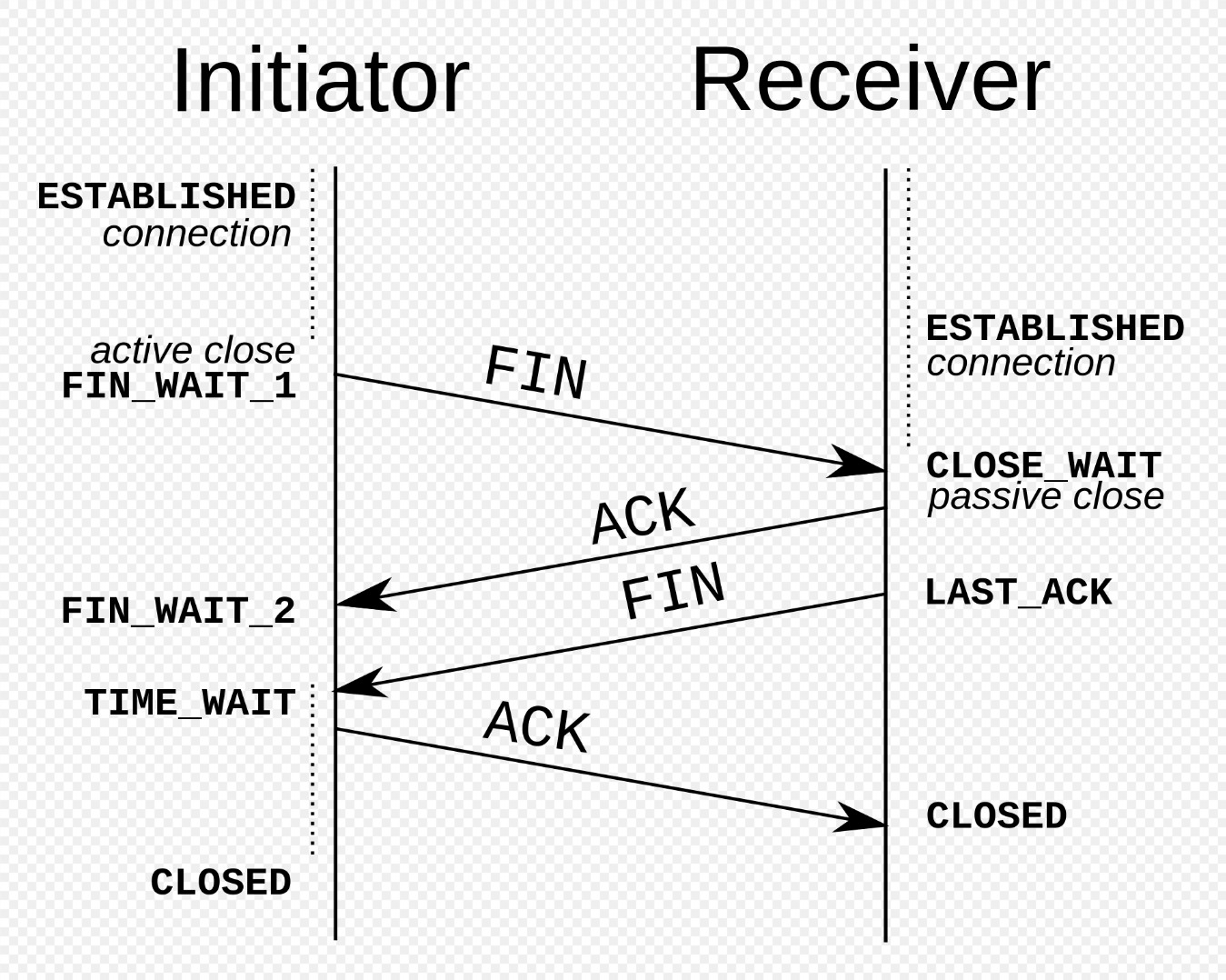
因为涉及到资源的释放和回收,挥手的操作相比握手要复杂一些,且不像握手阶段每个状态的切换都有对应的内核参数配置,挥手阶段的重传次数并没有明确的参数定义,更像沿袭传输过程的行为。在测试时通过iptables阻断特定数据包可以发
- 客户端主动断开连接后进入 FIN_WAIT_1,若超时未收到回包,则执行重发,直到收到应答进入 FIN_WAIT_2 状态,或者直接关闭连接
- 服务器被动断开连接后进入 CLOSE_WAIT,若立刻调用Close函数,则发送FIN包后进入 LAST_ACK 状态,等到客户端响应ACK包,若超时未收到回包,则执行重发,收到ACK包或完全超时后关闭连接。
总的来说,发送方未收到响应时会自动重传,接收到方收到请求时自动应答。
由于TCP是全双工的,服务端和客户端都可以主动发起挥手,这里以客户端主动挥手为例。
4.1 客户端发送FIN包
客户端发送FIN包后,进入 FIN_WAIT_1 状态,等待服务器响应ACK。我们可以使用这个命令,让服务器过滤已经处于ESTABLISHED状态的连接中的FIN+ACK包
1iptables -A INPUT -p tcp -m state --state RELATED,ESTABLISHED --tcp-flags ALL FIN,ACK --dport 12345 -j DROP
或者过滤掉服务端响应的ACK或FIN+ACK包
1iptables -A OUTPUT -p tcp -m state --state RELATED,ESTABLISHED --tcp-flags ALL ACK --sport 12345 -j DROP
2iptables -A OUTPUT -p tcp -m state --state RELATED,ESTABLISHED --tcp-flags ALL FIN,ACK --sport 12345 -j DROP
但为了方便抓包,我们还是尽量让数据回传到客户端,然后拦截客户端的请求。
客户端将进入 FIN_WAIT_1 状态且无法收到服务器回包,重传8次,超时后回收资源,删除连接。
4.2 服务端响应ACK包
理论上服务端接收到FIN包后,响应ACK包,进入 CLOSE_WAIT 状态,但一般情况下用户代码收到通知后,会立刻执行Close操作,那么回包中的FIN也会置位,服务端状态直接跳入 LAST_ACK 状态,如果仍旧需要做一些耗时清理操作导致延迟触发Close操作,那么就会停留在 CLOSE_WAIT 一段时间。
CLOSE_WAIT 属于被动关闭时产生的问题,大量出现时应该是处理不当导致,需要排查代码。
客户端接收到ACK后,进入 FIN_WAIT_2 状态,此时客户端主动发送通道关闭。客户端也有应对服务端迟迟不调用Close操作的情况, net.ipv4.tcp_fin_timeout 参数定义了 FIN_WAIT_2 状态最长持续多少秒,超时未收到FIN则直接关闭连接。
4.3 服务端发送FIN包
服务端发送FIN包后,进入 LAST_ACK 状态,等待客户端响应ACK,和客户端主动发送FIN包类似,若无法收到回报,重传8次,超时后回收资源,删除连接。
这里可以在客户端上拦截来自服务器的FIN包和FIN+ACK包,从而令服务器持续重发
1iptables -A INPUT -p tcp -m state --state RELATED,ESTABLISHED --tcp-flags ALL FIN --sport 12345 -j DROP
2iptables -A INPUT -p tcp -m state --state RELATED,ESTABLISHED --tcp-flags ALL FIN,ACK --sport 12345 -j DROP
4.4 客户端响应ACK包
客户端接收到FIN包后,响应ACK,进入 TIME_WAIT 状态,等待2MSL(Maximum segment lifetime)。这么做有两个目的:
- 防止ACK丢失时,服务端产生重发而客户端未响应,导致操作系统直接回复RST而不是正常的ACK
- 防止该端口被重用于创建新连接时,遗留在网络上的老数据进入新连接导致状态错乱
关于MSL时长,RFC 793中标准定义是2分钟,一些Linux发行版直接取两倍 net.ipv4.tcp_fin_timeout。
TIME_WAIT 属于主动关闭时产生的问题,大量出现时可以通过配置内核参数减少等待,加速回收或者复用。
5. 数据传输
LoRaWAN的传输过程和TCP类似,握手后传输速率都有一个慢启动的过程。节点初始速率使用扩频因子SF12(速度最慢,传播距离最远),初始发射功率使用最大发射功率。网关在接收时数据时会得到一个RSSI(信号强度)和SNR(信噪比)。简单来说信号越强,信噪比越高,意味着节点离网关越近,环境底噪越小。服务端将持续记录统计这些数值,过滤异常数据,最后输出可用的链路预算大小,利用LinkADR指令调整扩频因子和发射功率,从而达到数据传输更快而更省电的目的。
但是通信过程中,环境并不是稳定的。节点端存在探测机制,会要求服务端回包,以确认链路状态,如果没有收到回包,则提高扩频因子和发射功率,以提升传输距离,确保通信。服务端同样存在探测机制,假设环境突然劣化,节点开始无法稳定通信,也会下发LinkADR指令要求节点提高扩频因子和发射功率。
那么,现在来看一下TCP的处理机制。
5.1 TCP处理机制简述
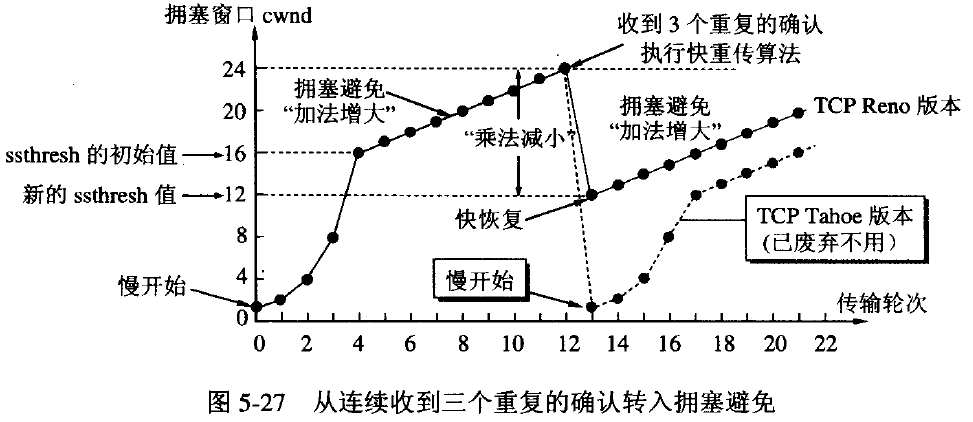
为了避免拥塞崩溃,TCP使用了多方面的拥塞控制策略。对于每个连接,TCP都维护一个拥塞窗口,从而限制了端对端传输中未确认的数据包总数。
在连接初始化或超时后,TCP使用 慢启动 机制来增加拥塞窗口,初始窗口大小较小(为MSS的整倍数),当每个分段得到确认时,拥塞窗口会增加一个MSS,使得在每个RTT内,拥塞窗口能够双倍增长。
当拥塞窗口超过慢启动阈值(ssthresh,slow start threshold)时,算法进入拥塞控制阶段,该阶段内只要未收到重复确认,就在每个RTT内增加一个MSS大小。
对于发送方,拥塞状态机的切换由ACK信息和定时器事件驱动,例如DUPACK、SACK、ECN-ECE标志的ACK、快速重传、重传超时等。
1/*
2 * Sender's congestion state indicating normal or abnormal situations
3 * in the last round of packets sent. The state is driven by the ACK
4 * information and timer events.
5 */
6enum tcp_ca_state {
7 /*
8 * Nothing bad has been observed recently.
9 * No apparent reordering, packet loss, or ECN marks.
10 */
11 TCP_CA_Open = 0,
12#define TCPF_CA_Open (1<<TCP_CA_Open)
13 /*
14 * The sender enters disordered state when it has received DUPACKs or
15 * SACKs in the last round of packets sent. This could be due to packet
16 * loss or reordering but needs further information to confirm packets
17 * have been lost.
18 */
19 TCP_CA_Disorder = 1,
20#define TCPF_CA_Disorder (1<<TCP_CA_Disorder)
21 /*
22 * The sender enters Congestion Window Reduction (CWR) state when it
23 * has received ACKs with ECN-ECE marks, or has experienced congestion
24 * or packet discard on the sender host (e.g. qdisc).
25 */
26 TCP_CA_CWR = 2,
27#define TCPF_CA_CWR (1<<TCP_CA_CWR)
28 /*
29 * The sender is in fast recovery and retransmitting lost packets,
30 * typically triggered by ACK events.
31 */
32 TCP_CA_Recovery = 3,
33#define TCPF_CA_Recovery (1<<TCP_CA_Recovery)
34 /*
35 * The sender is in loss recovery triggered by retransmission timeout.
36 */
37 TCP_CA_Loss = 4
38#define TCPF_CA_Loss (1<<TCP_CA_Loss)
39};
而如何处理拥塞,根据算法会有所差别,上图是TCP Reno和TCP Tahoe算法的处理机制,两者对于丢包事件判断都是以重传超时(retransmission timeout,RTO)和重复确认为条件。
对于重复确认的处理,两者有所不同:
- Tahoe:如果收到三次重复确认,进入快速重传,慢启动阈值改为当前拥塞窗口的一半,将拥塞窗口降为1个MSS,并重新进入慢启动阶段
- Reno:如果收到三次重复确认,进入快速重传,将当前拥塞窗口减半作为新的拥塞窗口和慢启动阈值,跳过慢启动阶段,进入 快速恢复 阶段
对于重传超时(RTO),两个算法都是将拥塞窗口降为1个MSS,然后进入慢启动阶段。
TCP在连接的过程中设置了许多钩子,将socket状态机传入拥塞控制算法,动态更新用于拥塞控制的相关参数。
如下是BBR模块的注册代码,可以看到许多提到过的关键字。
1static struct tcp_congestion_ops tcp_bbr_cong_ops __read_mostly = {
2 .flags = TCP_CONG_NON_RESTRICTED,
3 .name = "bbr",
4 .owner = THIS_MODULE,
5 .init = bbr_init,
6 .cong_control = bbr_main,
7 .sndbuf_expand = bbr_sndbuf_expand,
8 .undo_cwnd = bbr_undo_cwnd,
9 .cwnd_event = bbr_cwnd_event,
10 .ssthresh = bbr_ssthresh,
11 .min_tso_segs = bbr_min_tso_segs,
12 .get_info = bbr_get_info,
13 .set_state = bbr_set_state,
14};
15
16static int __init bbr_register(void)
17{
18 BUILD_BUG_ON(sizeof(struct bbr) > ICSK_CA_PRIV_SIZE);
19 return tcp_register_congestion_control(&tcp_bbr_cong_ops);
20}
21
22static void __exit bbr_unregister(void)
23{
24 tcp_unregister_congestion_control(&tcp_bbr_cong_ops);
25}
26
27module_init(bbr_register);
28module_exit(bbr_unregister);
拥塞控制算法注册函数中则检查了一些必须实现的方法。
1/*
2 * Attach new congestion control algorithm to the list
3 * of available options.
4 */
5int tcp_register_congestion_control(struct tcp_congestion_ops *ca)
6{
7 int ret = 0;
8
9 /* all algorithms must implement these */
10 if (!ca->ssthresh || !ca->undo_cwnd ||
11 !(ca->cong_avoid || ca->cong_control)) {
12 pr_err("%s does not implement required ops\n", ca->name);
13 return -EINVAL;
14 }
15
16 ca->key = jhash(ca->name, sizeof(ca->name), strlen(ca->name));
17
18 spin_lock(&tcp_cong_list_lock);
19 if (ca->key == TCP_CA_UNSPEC || tcp_ca_find_key(ca->key)) {
20 pr_notice("%s already registered or non-unique key\n",
21 ca->name);
22 ret = -EEXIST;
23 } else {
24 list_add_tail_rcu(&ca->list, &tcp_cong_list);
25 pr_debug("%s registered\n", ca->name);
26 }
27 spin_unlock(&tcp_cong_list_lock);
28
29 return ret;
30}
bbr_main函数在完成ACK包处理后会被调用,根据传入的socket状态机和发包率样本,更新内部状态机,并设置socket状态机的cwnd
1static void bbr_main(struct sock *sk, const struct rate_sample *rs)
2{
3 struct bbr *bbr = inet_csk_ca(sk);
4 u32 bw;
5
6 bbr_update_model(sk, rs);
7
8 bw = bbr_bw(sk);
9 bbr_set_pacing_rate(sk, bw, bbr->pacing_gain);
10 bbr_set_cwnd(sk, rs, rs->acked_sacked, bw, bbr->cwnd_gain);
11}
5.2 名词解释
拥塞窗口
我们都知道TCP头部中有一个窗口大小字段,发送方用该字段通告接收方自己当前的接收窗口大小。接收窗口提供了流量控制,而拥塞窗口控制的是全局网络的速率。即使接收窗口无穷大,也会因为链路原因产生丢包,收发双方需要对链路进行探测,因此可得:发送窗口 = min(rwnd, cwnd)。其中rwnd(receive windows)由对方通告,cwnd(congestion windows)由己方探测计算得出。
慢启动
慢启动是用于结合其他阶段算法,来避免发送过多数据到网络中而导致网络拥塞。启动时设置较小的初始拥塞窗口(如1、2、4或10个MSS,根据拥塞算法确定)。拥塞窗口在每接收到一个确认包时增加,每个RTT内成倍增加,发送速率随着慢启动的进行而增加,直到遇到出现丢失、达到慢启动阈值或者接收方的接收窗口进行限制。
线增积减
和性增长/乘性降低(additive-increase/multiplicative-decrease、AIMD)算法一种反馈控制算法,包括对拥塞窗口线性增加,和当发生拥塞时对窗口积式减少。多个使用AIMD控制的TCP流最终会收敛到对线路的等量竞争使用。
快速重传
快速重传(Fast retransmit)是对TCP发送方降低等待重发丢失分段用时的一种改进。TCP发送方每发送一个分段都会启动一个超时计时器,如果没能在特定时间内接收到相应分段的确认,发送方就假设这个分段在网络上丢失了,需要重发。这也是 TCP 用来估计 RTT 的测量方法。
Linux下定义 TCP_FASTRETRANS_THRESH 为3,当发送方收到4次相同确认号的分段确认(第1次收到确认期望序列号,加3次重复的期望序列号确认)时,则可以认为继续发送更高序列号的分段将会被接受方丢弃,而且会无法有序送达。发送方应该忽略超时计时器的等待重发,立即重发重复分段确认中确认号对应序列号的分段。
5.3 拥塞控制算法
拥塞控制算法的命名格式统一为 TCP+算法名称,Linux目前默认的拥塞控制算法为TCP Reno,但现在最热门的应该还是TCP BBR。从TCP协议栈中调用拥塞控制算法的注释就可以看出来:
1/* The "ultimate" congestion control function that aims to replace the rigid
2 * cwnd increase and decrease control (tcp_cong_avoid,tcp_*cwnd_reduction).
3 * It's called toward the end of processing an ACK with precise rate
4 * information. All transmission or retransmission are delayed afterwards.
5 */
6static void tcp_cong_control(struct sock *sk, u32 ack, u32 acked_sacked,
7 int flag, const struct rate_sample *rs)
8{
9 const struct inet_connection_sock *icsk = inet_csk(sk);
10
11 if (icsk->icsk_ca_ops->cong_control) {
12 icsk->icsk_ca_ops->cong_control(sk, rs);
13 return;
14 }
15
16 if (tcp_in_cwnd_reduction(sk)) {
17 /* Reduce cwnd if state mandates */
18 tcp_cwnd_reduction(sk, acked_sacked, flag);
19 } else if (tcp_may_raise_cwnd(sk, flag)) {
20 /* Advance cwnd if state allows */
21 tcp_cong_avoid(sk, ack, acked_sacked);
22 }
23 tcp_update_pacing_rate(sk);
24}
以往大部分拥塞算法是基于丢包(ack和acked_sacked)来作为降低传输速率的信号,而BBR则基于模型主动探测,使用网络最近出站数据分组当时的最大带宽和往返时间(rate_sample)来创建网络的显式模型,这意味着会有更高的吞吐量和更低的延迟。基于拥塞避免的算法将会被逐渐替代,而目前实现了cong_control方法的算法只有TCP BBR。
算法实现细节就不再展开了。
6. Linux内核参数
在CentOS 7(Linux Kernel 5.6.0)下进入 /proc/sys/net/ipv4,我们可以看到72个tcp开头的参数,这些参数都可以通过sysctl命令配置和调整。
- tcp_abort_on_overflow
- tcp_adv_win_scale
- tcp_allowed_congestion_control
- tcp_app_win
- tcp_autocorking
- tcp_available_congestion_control
- tcp_available_ulp
- tcp_base_mss
- tcp_challenge_ack_limit
- tcp_comp_sack_delay_ns
- tcp_comp_sack_nr
- tcp_congestion_control
- tcp_dsack
- tcp_early_demux
- tcp_early_retrans
- tcp_ecn
- tcp_ecn_fallback
- tcp_fack
- tcp_fastopen
- tcp_fastopen_blackhole_timeout_sec
- tcp_fastopen_key
- tcp_fin_timeout
- tcp_frto
- tcp_fwmark_accept
- tcp_invalid_ratelimit
- tcp_keepalive_intvl
- tcp_keepalive_probes
- tcp_keepalive_time
- tcp_l3mdev_accept
- tcp_limit_output_bytes
- tcp_low_latency
- tcp_max_orphans
- tcp_max_reordering
- tcp_max_syn_backlog
- tcp_max_tw_buckets
- tcp_mem
- tcp_min_rtt_wlen
- tcp_min_snd_mss
- tcp_min_tso_segs
- tcp_moderate_rcvbuf
- tcp_mtu_probe_floor
- tcp_mtu_probing
- tcp_no_metrics_save
- tcp_no_ssthresh_metrics_save
- tcp_notsent_lowat
- tcp_orphan_retries
- tcp_pacing_ca_ratio
- tcp_pacing_ss_ratio
- tcp_probe_interval
- tcp_probe_threshold
- tcp_recovery
- tcp_reordering
- tcp_retrans_collapse
- tcp_retries1
- tcp_retries2
- tcp_rfc1337
- tcp_rmem
- tcp_rx_skb_cache
- tcp_sack
- tcp_slow_start_after_idle
- tcp_stdurg
- tcp_synack_retries
- tcp_syncookies
- tcp_syn_retries
- tcp_thin_linear_timeouts
- tcp_timestamps
- tcp_tso_win_divisor
- tcp_tw_reuse
- tcp_tx_skb_cache
- tcp_window_scaling
- tcp_wmem
- tcp_workaround_signed_windows
7. 流量统计
在测试握手和挥手时,iptables命令发挥了很大的作用,除了数据包拦截外,还可以进行流量统计,例如我们可以首先使用iftop或nethogs统计下短时间内哪些端口、IP访问频繁,然后添加对应规则,获取到统计结果。
以443端口为例,统计从该端口流入和流出的TCP数据包流量
1iptables -t filter -A INPUT -p tcp --dport 443
2iptables -t filter -A OUTPUT -p tcp --sport 443
运行一段时间后,查看数统计
1iptables -n -v -L -t filter
输出
1Chain INPUT (policy ACCEPT 195K packets, 145M bytes)
2 pkts bytes target prot opt in out source destination
3 2365 118K tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:443
4
5Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
6 pkts bytes target prot opt in out source destination
7
8Chain OUTPUT (policy ACCEPT 1426K packets, 4834M bytes)
9 pkts bytes target prot opt in out source destination
10 2076 20M tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp spt:443